Highlights from AAAI 2020
Earlier in February I was at the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20) to get a better feel for the general trends of the field and learn as much as I could (I did not to present anything, though). It was time well-spent. In this post I summarize some of the points that were particularly interesting to me. Since there was so much great content, it would be very difficult to summarize each presentation or talk. Instead, I will group it all in common themes and address the theme as a whole, commenting on the key points that showed up in a related presentation. The complete schedule and papers can be found through the official guide. Furthermore, many of the keynotes are available online for viewing now, I strongly recommend watching most of them, truly thought-provoking material.
Healthcare
Healthcare was a pervasive theme. There was an excellent tutorial about Precision Medicine, many regular research papers that addressed health issues, a workshop on Health Intelligence (which unfortunately I could not attend because it was sold out), and a special edition of AI in Practice dedicated to the theme with excellent keynotes. I find all this revealing, since it suggests that this might very well be one of the next booming sectors in information technology, like financial services before it. Key points:
- There are a number of datasets available for research and development:
- Verily Life Sciences sponsors Project Baseline, an initiative to comprehensively map clinical data from trials, surveys and other sources.
- Drug repurposing is a topic that showed up a few times. It concerns in the use of existing drugs and their related studies in new applications. Systematic computational support to this task is valuable. See the paper: Chemical and Textual Embeddings for Drug Repurposing
- There are drug knowledge bases useful for computational applications (see paper: Drug knowledge bases and their applications in biomedical informatics research):
- Some medical conditions are very specific, which makes directly related data scarce. In fact, Precision Medicine is all about very small amounts of data (i.e., only one subject, the patient under consideration). Therefore, approaches that leverage Transfer Learning are of great interest. Meta-Learning is also a potential way to tackle the problem (e.g., MAML, see paper: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks).
- Some interesting papers:
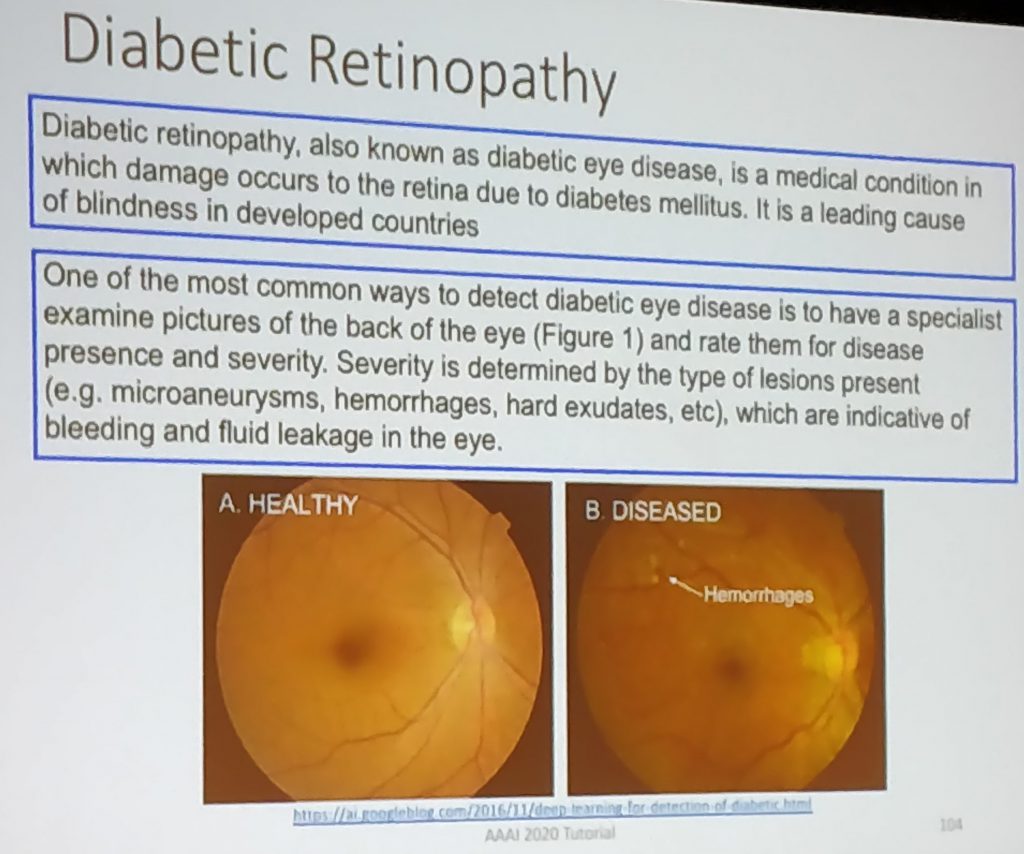
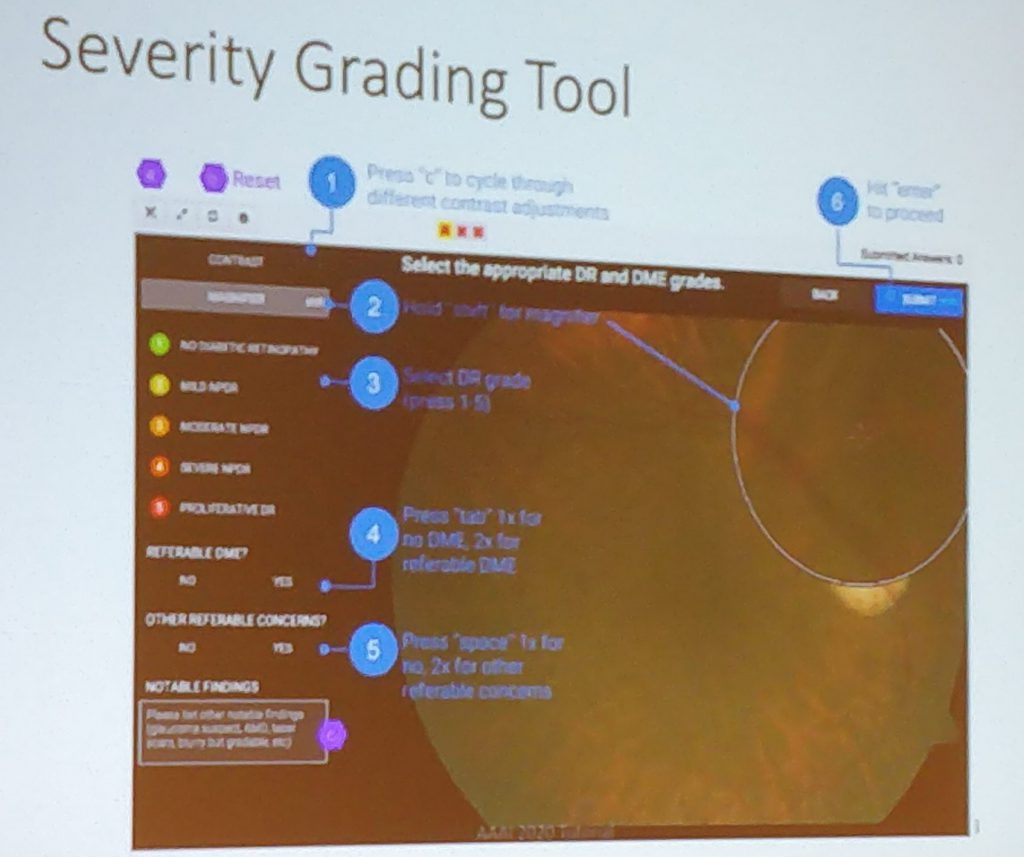
- A famous result, cited by various researchers: Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs
- AI in Health: State of the Art, Challenges, and Future Directions.
- Machine Learning and Prediction in Medicine — Beyond the Peak of Inflated Expectations
- A clinically applicable approach to continuous prediction of future acute kidney injury
- International evaluation of an AI system for breast cancer screening
- MetaPred: Meta-Learning for Clinical Risk Prediction with Limited Patient Electronic Health Records
- Intelligible Models for HealthCare: Predicting Pneumonia Risk and Hospital 30-day Readmissio
- A New Initiative on Precision Medicine
- Data augmentation can be useful to train ML models, as it was shown by a paper that used GANs to improve ECG classification with synthetic data. The reason this works is that ECG data is quite structured and so a generator can learn its overall pattern and extrapolate. This has clear implications not only for ECGs, but also for all kinds of structured time series data. See the paper: Improving ECG Classification using Generative Adversarial Networks
- ML can be used for patient rehabilitation by proper understanding of motion classes. See the paper: Combining Real-Time Segmentation and Classification of Rehabilitation Exercises with LSTM Networks and Pointwise Boosting
- Cities can be (semi-)automatically designed in a way to improve health outcomes. This is one of the goals of the impressive generative urban design approach shown by Sidewalk Labs in a keynote.
- CareJourney, a company that deals with population health analytics, not unlike my own employer.
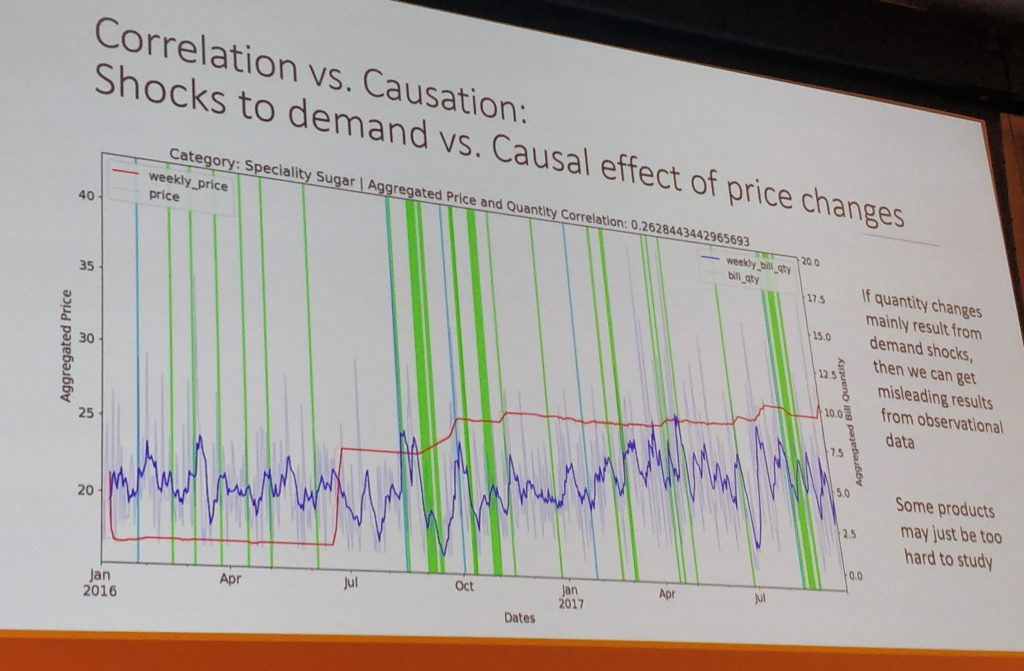
- Beware of causal confounding. Your data may be cheating.

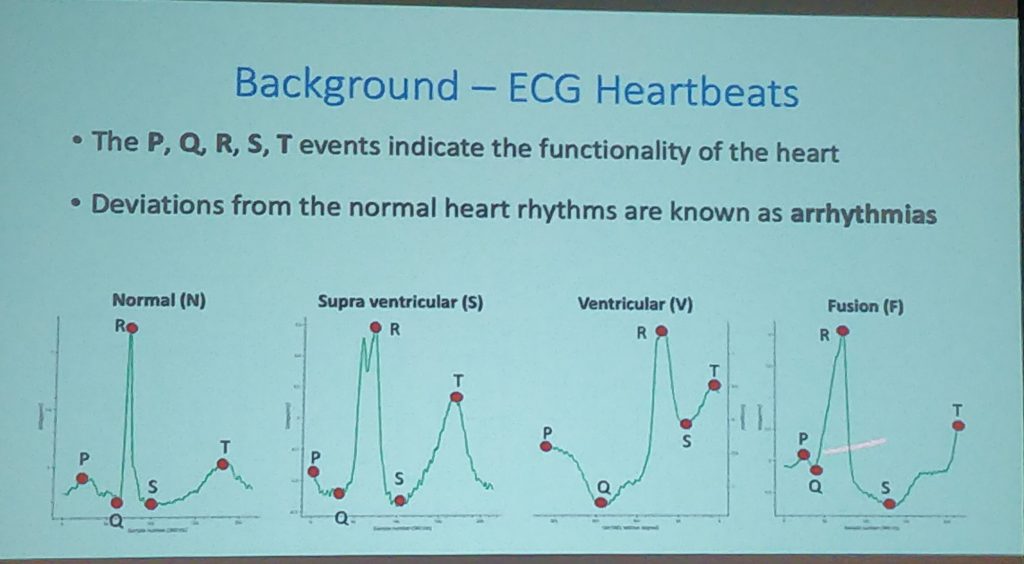

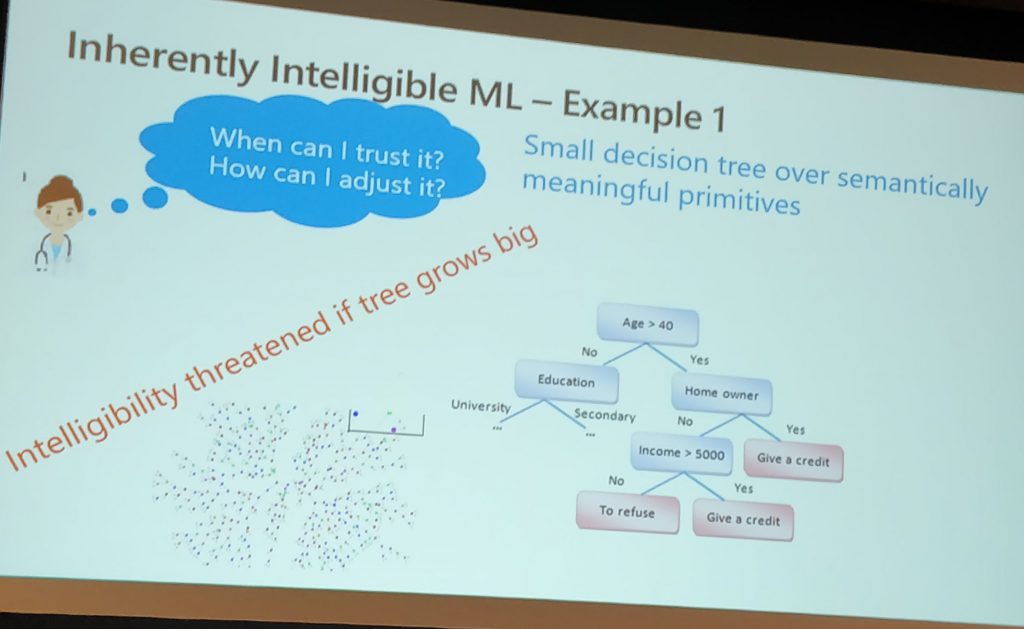
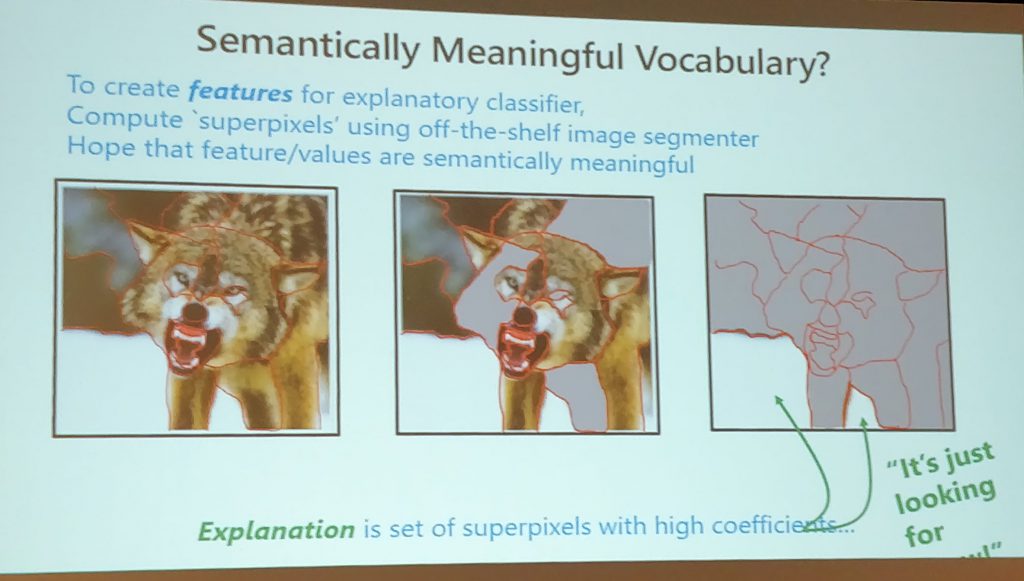
Intelligibility
Intelligibility is a more complex subject than I had realized.
- Models might appear to be good, but in reality might be optimizing completely wrong things.
- Mixed human/machine teams obviously need to cooperate.
- Model output is not the only valuable result. Human insight, which might lead to other valuable results, is also important, and is promoted by transparent models.
- Models that are explainable promote trust. However, one must know when to trust! Trust itself might be just a form of deception.
-
“King Midas problem”: difficulty to precisely define a goal.
-
Machines could instead learn preferences from observing human behavior. However, this might lead to non-democratic results (because, essentially, some people make more mistakes than others). See the paper: Negotiable Reinforcement Learning for Pareto Optimal Sequential Decision-Making
- Microsoft provided some great material on designing interactive AI systems.
- A notable application in healthcare: Intelligible Models for HealthCare: Predicting Pneumonia Risk and Hospital 30-day Readmissio
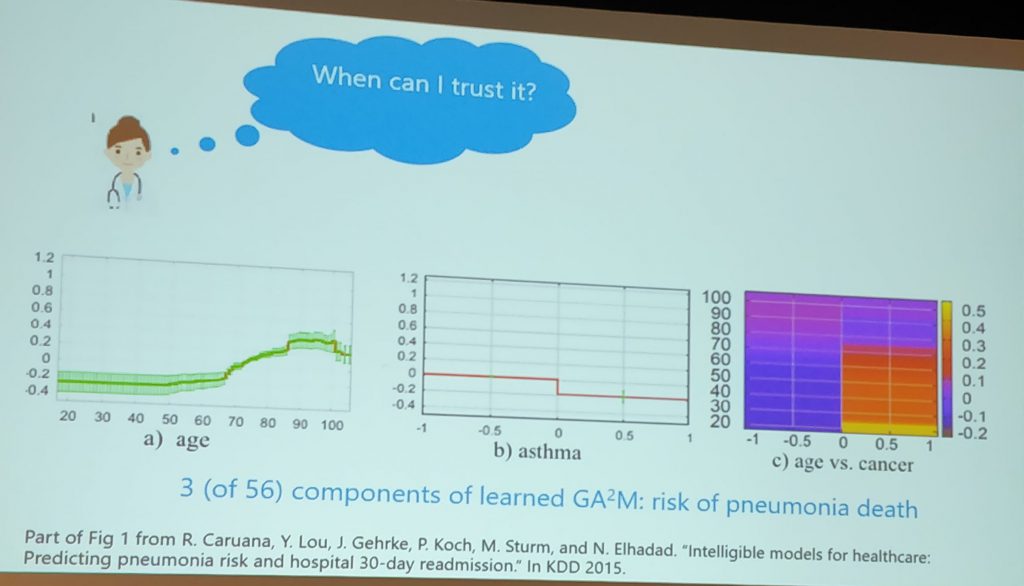
Risk and Hospital 30-day Readmission.”
Causal Inference
Causality was also a very popular theme.
- Deep representation learning can be applied to causal inference by properly positioning treated and control subjects in a new representation space that makes matching easier. Moreover, it also allows the study of individual treatment effect (ITE) and not just average treatment effect (ATE). ITE would be useful, for instance, in Precision Medicine, allowing to prescribe causally-relevant treatments considering each patient specific needs. These topics were explored in a tutorial. The slides and a related survey on causal inference by the presenters are available.
- Causal inference libraries:
-
DoWhy, by Microsoft, in Python.
-
Causal ML, by Uber, in Python.
-
EconML, by Microsoft, in Python.
-
causalToolbox, in R
-
CausalNex, by QuantumBlack, in Python.
-
CausalImpact, by Google, in R. There’s a Python implementation by Dafiti.
-
- It was recognized by many people that notions of causality should be incorporated in Machine Learning methods, notably Deep Learning. That is to say, causality is an important prior that can be assumed as given by learning algorithms.
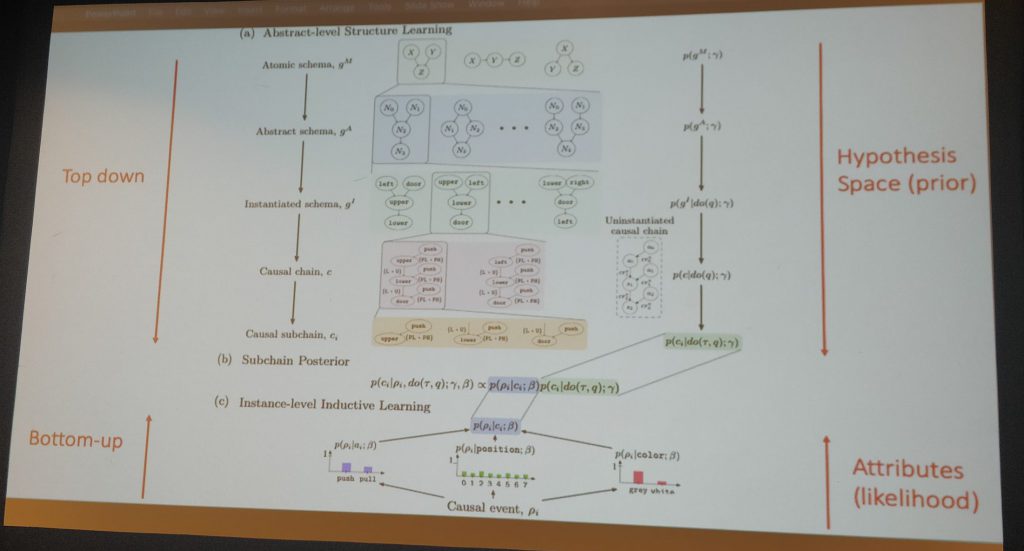
- Abstract structures for causal knowledge can be combined with Reinforcement Learning to promote efficient transfer learning. In the reported experiments, this approach speeds up learning in new environments at least by an order of magnitude. See the paper: Theory-Based Causal Transfer: Integrating Instance-Level Induction and Abstract-Level Structure Learning
- Counterfactuals are important to understand consumer preferences, particularly pricing. Being able to predict events from past data is not enough, one must be able to formulate questions concerning new scenarios. For example, coffee sales predict diapers sales, but that does not mean that by actively trying to sell more coffee (e.g., through discounts) one can sell more diapers. Past data may allow one to model consumer preference and price-sensitivity, thus allowing counterfactual inferences. Some relevant papers:

Scientific Discovery
Scientific discovery is a form of learning and therefore should be subject to computational reasoning.
- Yolanda Gil gave a great talk on the subject.
- Wikidata, which curates structured information for Wikipedia and related sites, is now very popular (we were told it is now growing faster than Wikipedia itself).
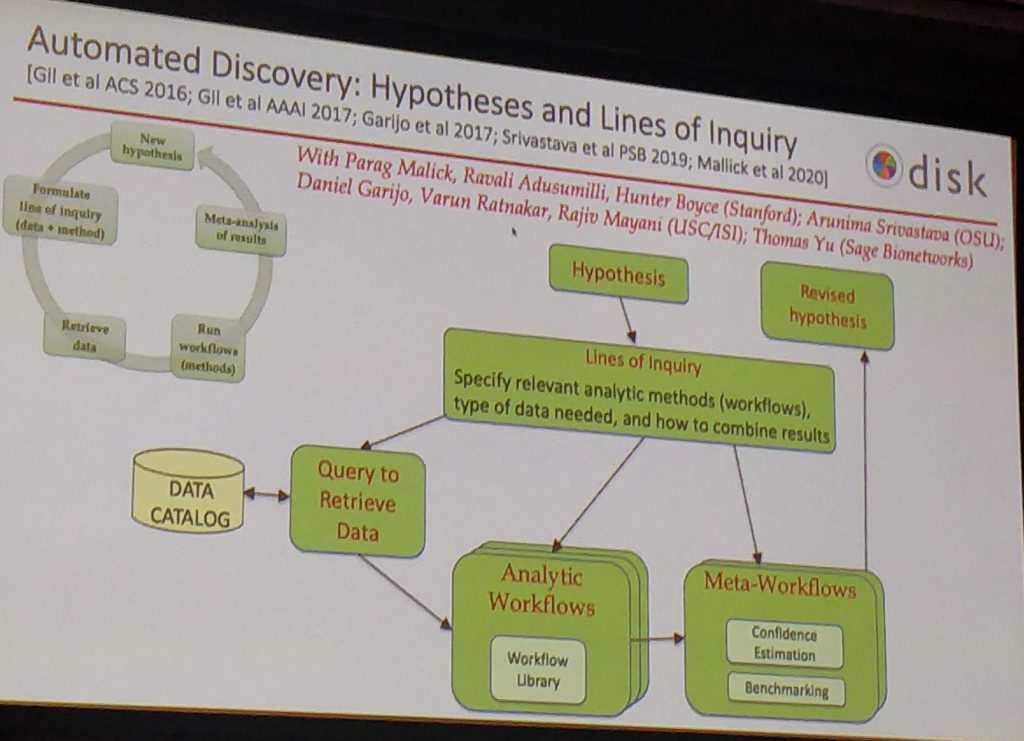
- Scientific research is increasingly computational. See the DISK project and related papers:
- Some important elements:
- Formulation, test and revision of hypotheses.
- Reusable fragments of scientific workflow.
- Compositionality of scientific knowledge.
- Knowledge-driven discovery, through which past discoveries can inform and guide new ones.
- It is puzzling that the nuances of computational scientific discovery do not find their way into general Machine Learning approaches. Surely what works for natural science should be helpful in other areas such as business applications! I was told this was about lack of funding, but I am not convinced. I remain puzzled. See also my page on Experiment-Oriented Computing.

Games and AI
Games are an interesting way to explore intelligence and recently we have seen impressive progress. However things are not so simple.
- Debate on the subject.
- Because games provide an objective performance criteria, they help to direct research and results.
- Furthermore, humans seem to be hardwired to enjoy playing, so games are intimately related to human behavior.
- However, it seems that so far learning in one game has not been transferable to another. Hence, present techniques, amazing as they are, fail in this crucial aspect of intelligence. See also: On the Measure of Intelligence
- Garry Kasparov also pointed out (authoritatively, I guess) that “aptitude for playing chess is nothing besides aptitude for playing chess.”
- Humans are open-ended and intentional, different from games, which are typically much more restricted.
- AI and humans might actually work better together in games, which suggests that present technology fails to capture some important part of human intellect, event in these restricted applications.
- “Augmented Intelligence” might be a better goal than “Artificial Intelligence.” I sympathize.
Relational Information Extraction and NLP
There was a lot of NLP content. What caught my attention, though, was mostly related to information extraction. With such techniques it would be possible to effectively transform human into machine knowledge (e.g., scientific or business texts to logical sentences). For example:
- BERT (and similar language models) can be used to extract relational information. See the paper: Inducing Relational Knowledge from BERT
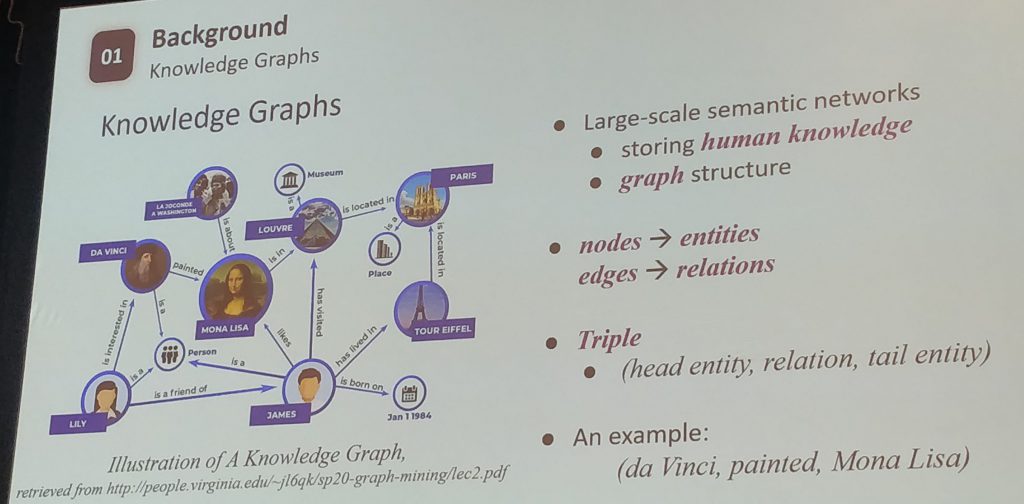
- Knowledge graphs can be built incrementally in a semi-supervised manner, which makes their construction much easier. See the paper: Neural Snowball for Few-Shot Relation Learning
- Hierarchical modelling for entity embedding in knowledge graphs can be useful for filling in missing relational information. See paper: Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction
- I learned about two new frameworks: Forte for NLP; and related Texar, a more general ML toolkit
Philosophical Aspects: attention, priors, compositionality and more
The special edition with the Turing Award laureates, as well as the talk with Daniel Kahneman, brought some interesting reflections about where the field should go.
- Turing Award laureates special event was filmed.
- The chat with Daniel Kahneman is also available for viewing.
- Self-supervised learning is one way to use available data more effectively, since it eliminates the need for manual labeling.
- Intelligence is about prediction, therefore forward models of the world are useful.
- Why would evolution lead to conscious bottleneck? Attention mechanisms (e.g., Transformers) in neural networks might provide a clue.
- Symbols work as abbreviations of more complex descriptions (“big vectors of stuff happening”).
- System 1 (unconscious) process things in parallel and gives meaning to concepts. System 2 (conscious) works sequentially by “calling operations of System 1”. This description of the human mind suggests artificial neurosymbolic systems.
- Priors are important to proper learning. One must assume things to learn. The difficulty might be to figure out the proper priors. Causality seems to be one of them.
- Compositionality of learning would allow much better generalization, including the invention of new concepts, a key characteristic of intelligence.
- Language models ultimately cannot just be “just about words.” They must be grounded in reality somehow.
- Environment is essential for intelligence. Things have meaning with respect to contexts. Such environments, however, can be artificial and different from our own human reality.
- When I asked about how to find ideas and prioritize them to the Turing laureates, we were told that the important thing is to have good intuition, to find the crux of the problem at hand and then just work stubbornly on it.



Other Themes and Results
- Reinforcement learning can be combined with formal methods. A temporal logic formula can act as a “restraining bolt” that modifies rewards according to the agent’s compliance. See the paper: Restraining Bolts for Reinforcement Learning Agents
- Social media actually modifies people algorithmically in order to generate clicks (i.e., revenue). A practical example of how optimization goals can lead to strange (unintended?) consequences.
- Generative urban design can be achieved by combining human know-how an taste with algorithmic exploration, as show by Sidewalk Labs. This reminds me of Interactive Evolutionary Computation, a subject on which I published before (in the context of UI optimization): User Interface Optimization Using Genetic Programming with an Application to Landing Pages
- Traffic is also subject to optimization via multiagent simulations, used by Replica.
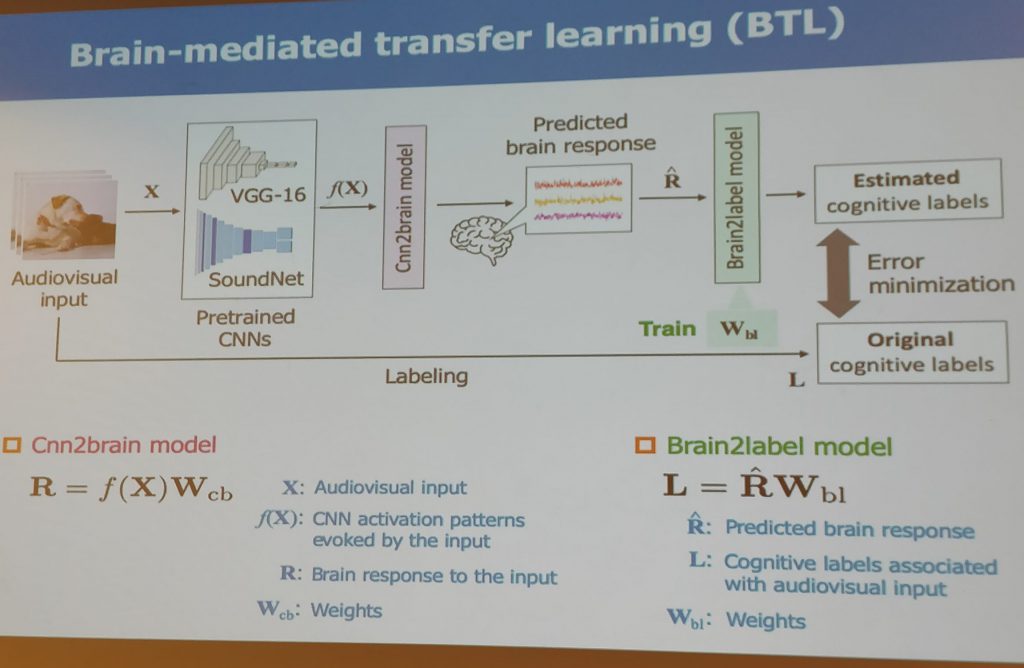
- Amazingly, it is possible to combine brain predictions with ML models, as shown in the paper Brain-Mediated Transfer Learning of Convolutional Neural Networks!
- Stuart Russell gave us two literary recommendations related to our academic anxieties: