Highlights from AAAI 2021: papers, insights, datasets and tutorials
(Please feel free to reach me out if you want to talk about some specific point made here or just casually brainstorm w.r.t. these themes, I’d love to chat.)
Earlier this month, I attended the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), which took place in an entirely virtual format. This time, I focused my attention mostly on matters pertaining to the interaction of human and artificial agents, notably involving Natural Language Processing — I like to say that I prefer to work with augmented human intelligence, rather than just an artificial one. I also noted a few larger themes in terms of techniques and issues that continue to gain ground in the AI community. Here I present some content highlights and insights I got from this perspective, including material from co-located tutorials and workshops. My favorite works or themes are marked with a ⭐️, and related datasets are emphasized with a 🗃️ (it is always good to have varied datasets available after all).
It is important to note that, while specific formulations of problems and solutions are of course important, it is perhaps even more interesting to consider the general types of problems and solutions. This opens up the imagination for new possibilities in one’s own particular problems and might just provide the right insight with which one can address them in a new way. Furthermore, perusing a good paper’s related works section is often a very good way to learn about the state-of-the-art in the field, which might be hard to find otherwise.
There were some general, horizontal, trends that touched many of the developments presented, notably:
- Meta Learning, AutoML and Transfer Learning are all gaining ground, showing that reuse is a central theme in Machine Learning.
- Reinforcement Learning applications and technical improvements.
- Unsupervised and self-supervised methods.
- Graph Neural Networks.
- Causal Inference.
- Neuro-symbolic approaches. I find this particularly interesting, because it is a way to combine precise human insight and guidance with powerful neural learning.
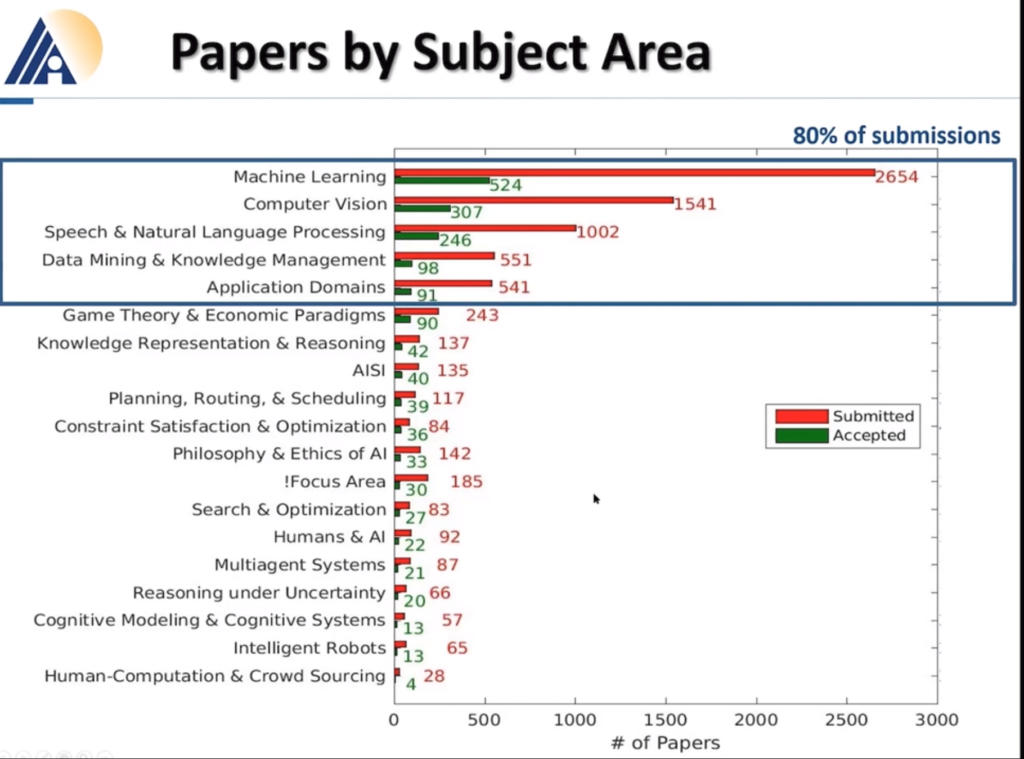
We can also see the main subject of the papers presented:
If you enjoy this post, you might like my previous highlights from AAAI 2020 and from KDD 2020 as well.
Remote Conference Format
Before diving into the conference’s content, let us begin by considering the remote format, which of course is itself an interesting point. This is the second large-scale academic conference I attended in this manner (the first was KDD 2020), so I feel now capable of making some constructive observations.
- The interaction among participants happened in a game-like 2-D simulation of physical environments using gather.town. Overall, I felt this was a bad decision, because it included the bad aspects of physical space (i.e., having to walk long distances) without too much of its qualities (i.e., promoting random encounters and discussions). To be fair, I did wandered around and gained some insight from this, but it is not even close to an actual physical version. For example, when you go through someone there’s no eye contact (or any body language) to suggest whether the person is available or not. The approach taken by KDD 2020 was more traditional and better – they offered chat rooms. Yet, it was fun (and rather eery) to enter in poster sessions and have the camera automatically turning on.
- The sessions themselves where mostly abolished, and instead participants were asked to see the pre-recorded videos and visit authors in the poster sessions. I have mixed feelings about this. It could have worked much better if it was easy to watch all videos for a session at once. Unfortunately, that was not the case, participants had to hunt each paper page, where the corresponding video was located. This made the whole experience very inefficient, and I’d rather have had live sessions as in KDD 2020.
- Papers were hard to find because the conference program did not have links to them, and the paper search interface did not group them in any way, it just allowed to search specific keywords. Having thousands of papers available, this is really not enough. A conference program app like Whova, used in KDD 2020, would have helped a lot. To be fair, each paper page had an effective “related papers” section, which helped a lot.
For the future, I’d recommend the following:
- Have pre-recorded sessions, instead of just individual talks, thus one can watch all related talks at once. And organize the conference program in a dedicated app such as Whova, with working links for everything.
- Have separate poster sessions to talk with the authors, that was actually a good AAAI 2021 idea.
- Encourage interaction through forums or chat rooms. Although one can argue that such interaction is possible outside the conference, it is important to realize that during the conference people are making their scarce time available synchronously, and that’s the real value that such an event brings from a social perspective.
- More complex social networking mechanisms could be useful. For example, make it easier to locate people with similar interests and book conversations (individual or in groups). This is actually harder to do in person, so that’s an area where the digital experience can add considerable value.
- It would be interesting to continue experimenting with some form of 2-D space simulation. However, to be valuable, it would have to be a far more informative environment that the simple 8-bit-like gather.town. For one thing, it would be useful to see the content of elements on the space (besides their title), from a distance, without having to “enter them”. Furthermore, the automatic camera was actually quite interesting, and I’d recommend to keep such a feature.
Natural Language Processing
Natural Language Processing (NLP) is essential to the coordination of humans and artificial agents, so that’s something I paid considerable of attention to. There were many different relevant aspects of NLP, which I review below.
Recent Advances
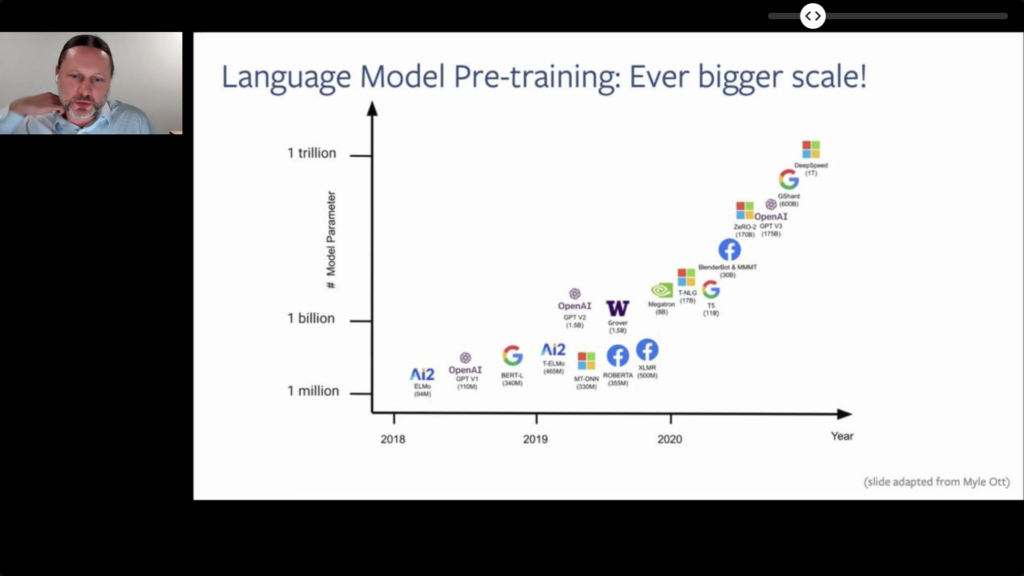
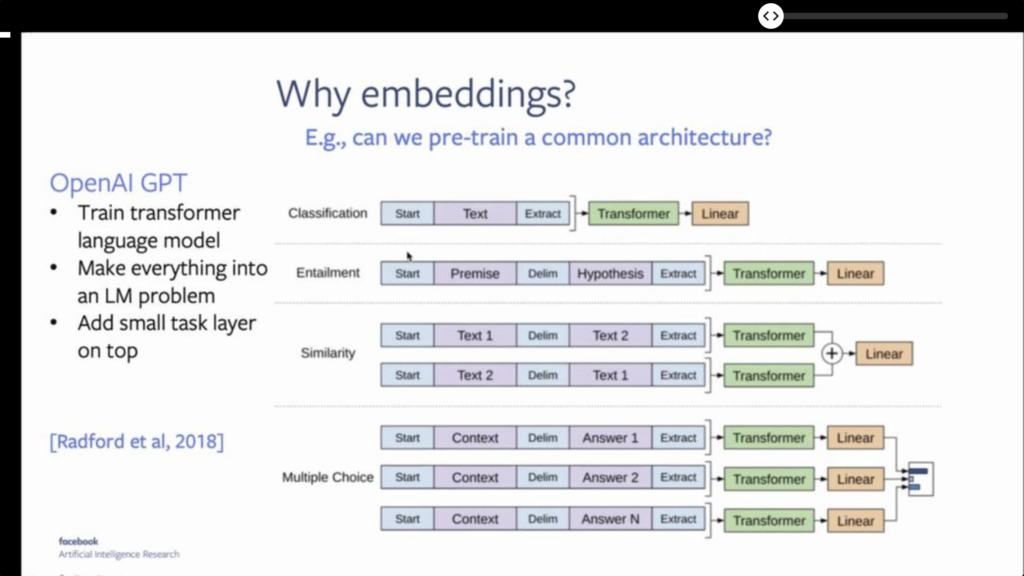
There was an invited talk on Recent Advances in Language Model Pretraining, covering the main Transformer-based techniques that arose in the last few years (ELMo, BERT, GPT-2/3, etc).
- It is interesting to note that language models, understood as probability distributions over sentences, became the sole type of model needed starting with GPT through a common pre-trained architecture.
- BERTology: NLP is advancing so rapidly that nobody really knows why these sophisticated models work, particularly Transformers. Tellingly (and rather amusing), there’s actually a “field of study” of BERT / Transformer models (see A Primer in BERTology: What We Know About How BERT Works).
Natural Language and User Understanding
Extracting meaning from language is of course critical to understand what humans intend. Thus, Natural Language Understanding (NLU) is perhaps one of the most important areas to help machines understand us.
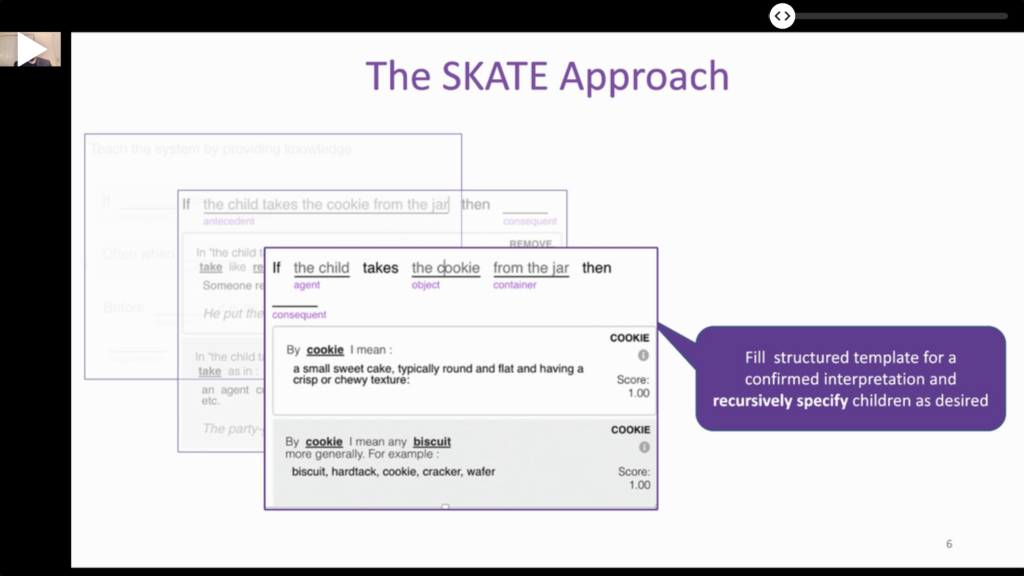
- ⭐️ SKATE: A Natural Language Interface for Encoding Structured Knowledge. This paper shows a very fruitful combination of User Interface design with NLU. There’s no good reason to leave users in the dark when they type something. This work shows one clever approach to continually help users express themselves, which also helps (a lot) the underlying algorithms! This suggests that tight cooperation between UI/X and Machine Learning groups is critical.
- i-Parser: Interactive Parser Development Kit for Natural Language Processing. Different languages and applications have different requirement.
- ⭐️ Knowledge-Driven Natural Language Understanding of English Text and its Applications. Statistical approaches are highly successful, but that does not mean that symbolic methods cannot add value, e.g., because many domains of interest can benefit from precise specifications. This work uses logic programming to perform NLU reasoning using the s(CASP) system based on the Ciao language.


- ⭐️ There are some established meaning representation conventions in Computational Linguistics, which can be used to reason over extracted linguistic information:
- Abstract Meaning Representation (AMR). A graph-based meaning specification format, used in a number of conference works (commented elsewhere in this post).
- Meaning Representation Parsing (MRP). A type of task used to evaluate meaning parsing strategies.
- The SIGNLL Conference on Computational Natural Language Learning (CoNLL) is a related (but of course broader) and prestigious event.
- ⭐️ Text-To-SQL is a common NLP task I was not aware of. It looks like a very interesting direction to explore, not only for SQL, but also for other specification and programming languages. Results are encouraging and I feel that failures could also be addressed through interactive refinement. There ware some papers on this, and I also learned about related datasets:
- Tracking interaction States for Multi-Turn Text-to-SQL Semantic Parsing
- Leveraging Table Content for Zero-Shot Text-to-SQL with Meta-Learning
- 🗃️ Datasets: WikiSQL, CoSQL, SParC, ESQL (Chinese).

- ⭐️ Inverse Reinforcement Learning with Natural Language Goals. How to transform a user request into a sequence of (robotic) actions? That’s the problem here. The authors show how to learn a reward function for a Reinforcement Learning algorithm, essentially through exploration of the environment, which then can be used to accomplish the goals requested.
- 🗃️ They use the Room-to-Room dataset, which is itself quite impressive.
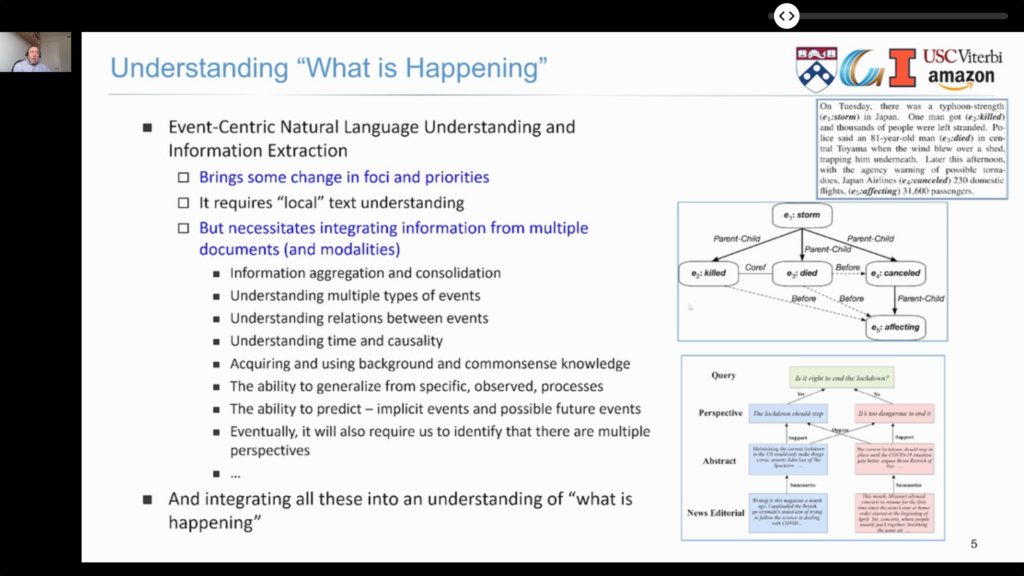
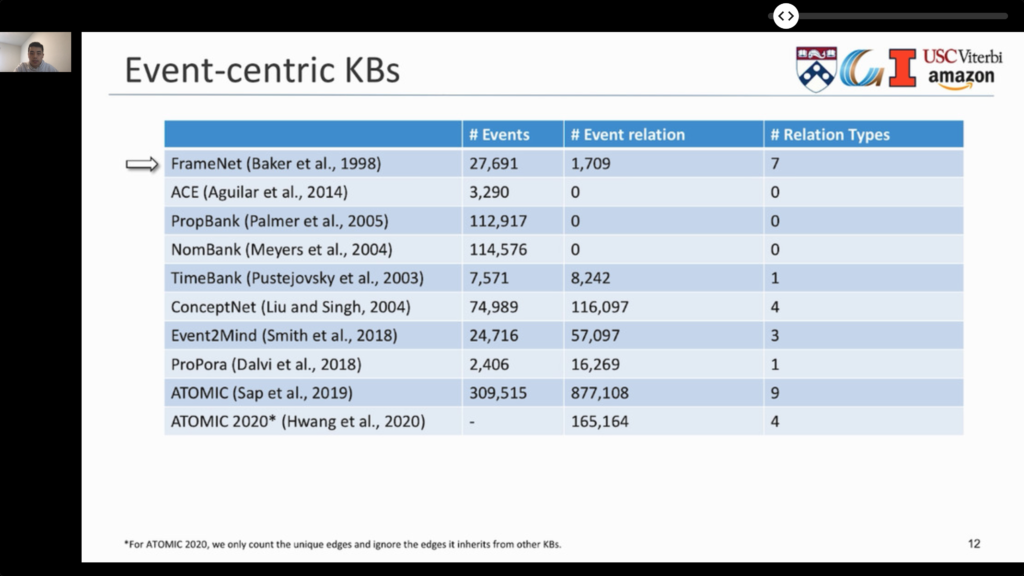
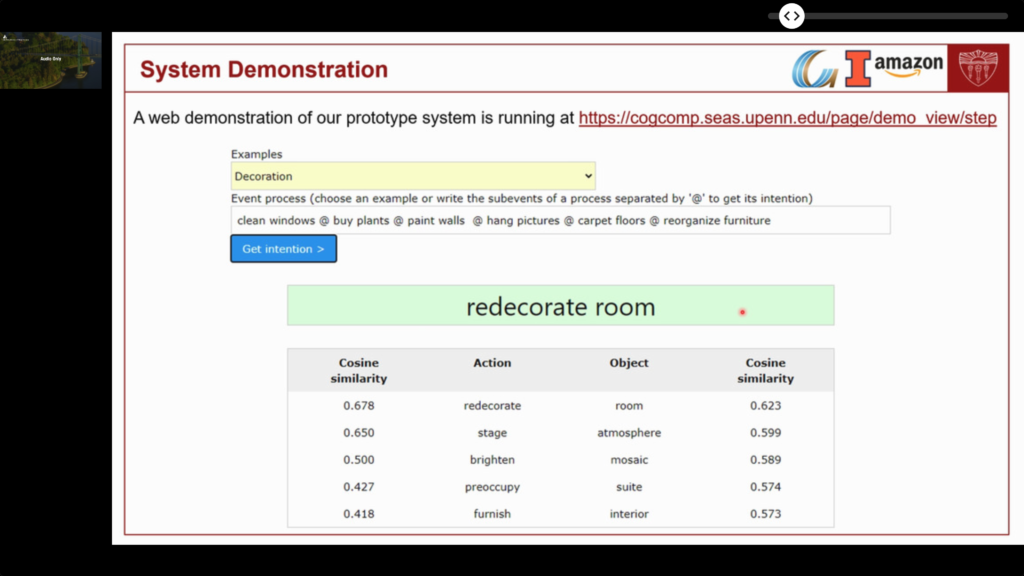
- Events, which describe “what happened”, can be a rich source of conceptual structures for NLU. There was a detailed tutorial: Event-Centric Natural Language Understanding.
- Events can have sub-events, causal and temporal relationship.
- They can combine multi-modal representations (e.g., text and images).
- They describe processes over time.
- You can try their tool online.
- 🗃️ Related datasets: WikiHow-Dataset (useful for process modeling), TORQUE, Event2Mind (“commonsense inference on events, intents and reactions”).
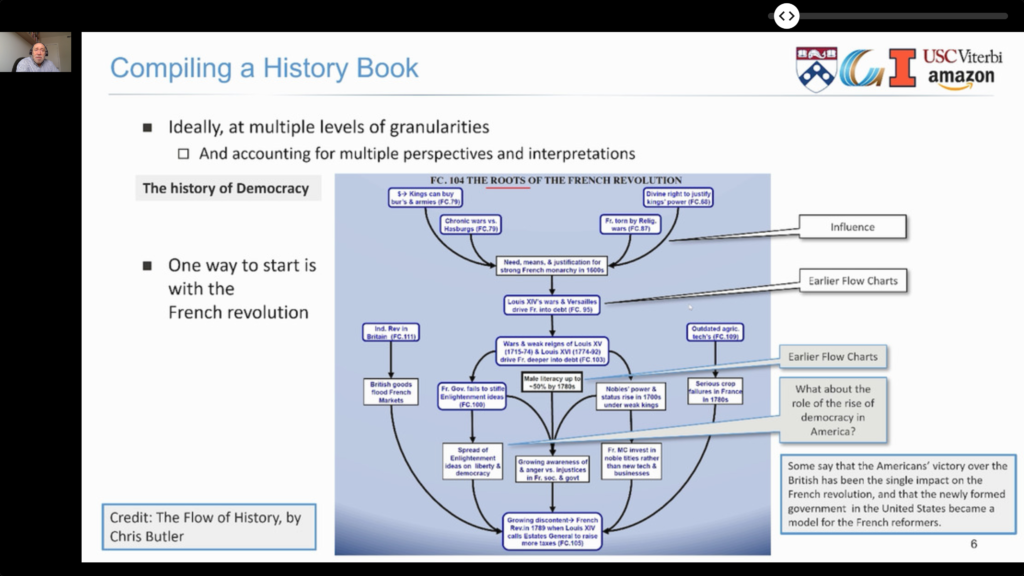
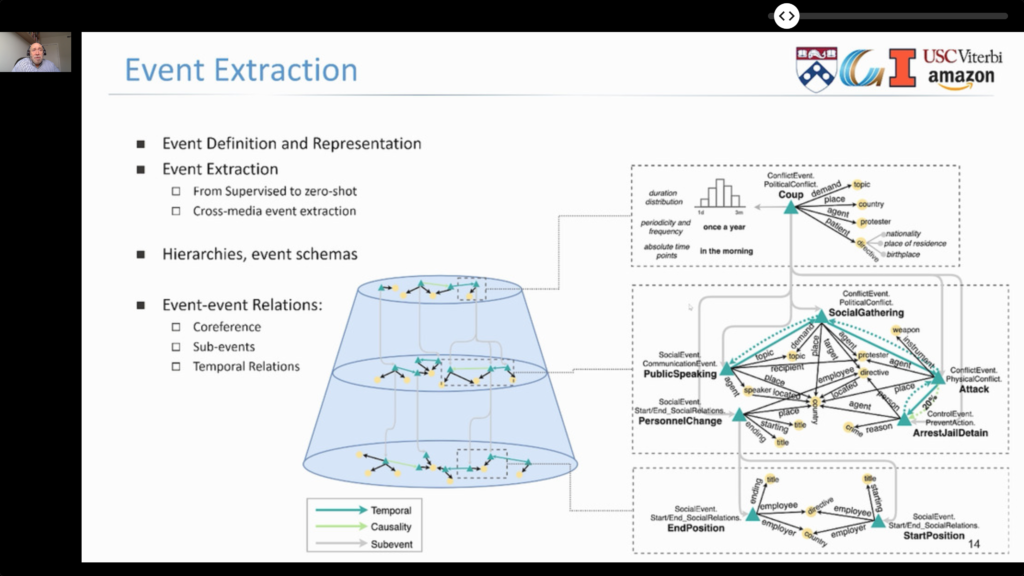
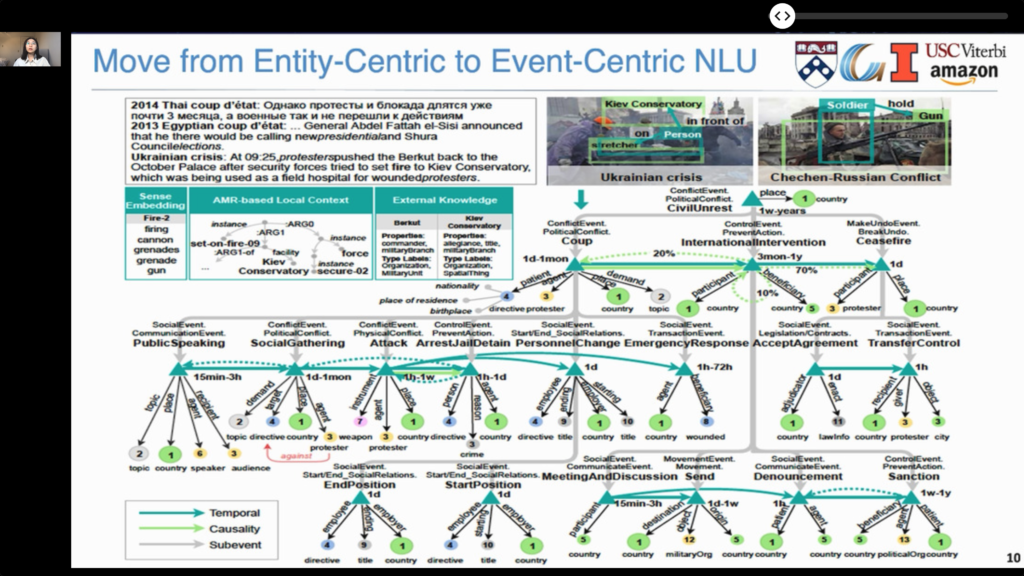
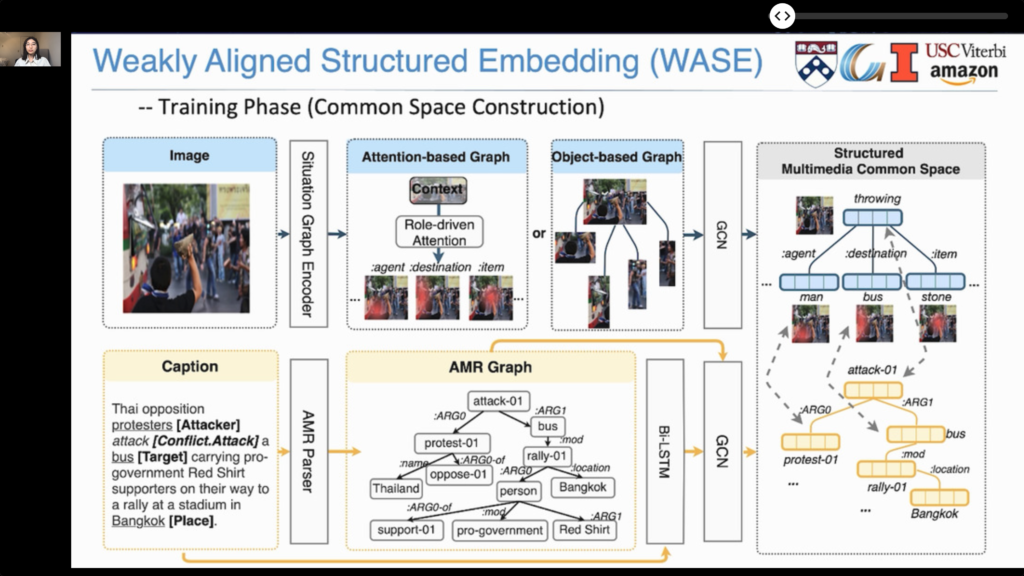
Knowledge Extraction and Decision Support
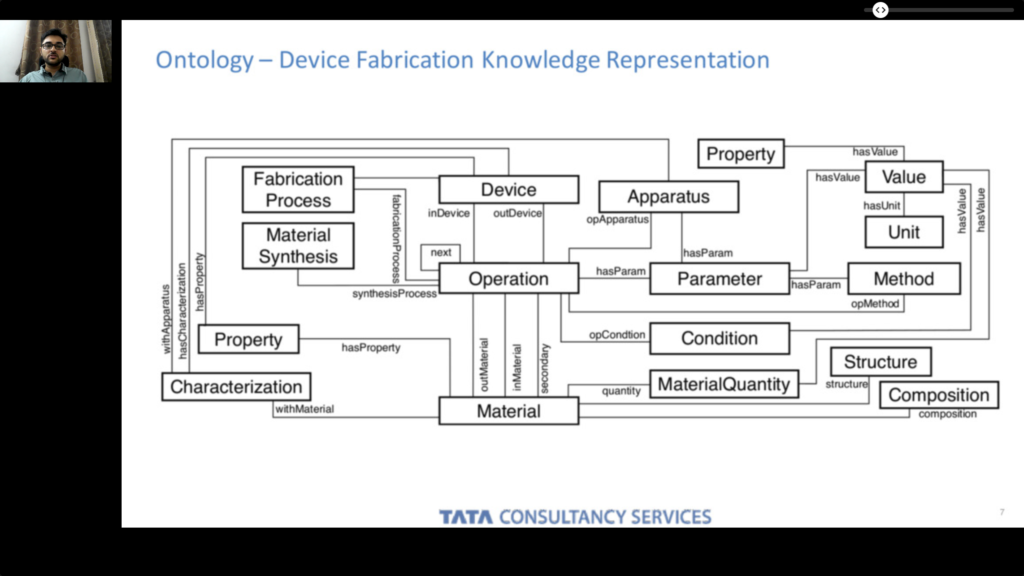
- Device Fabrication Knowledge Extraction from Materials Science Literature. Knowledge extraction can benefit from highly structured domains and related ontologies. Even if the precision and recall of the extracted information is not perfect, it can nevertheless be used as a decision support system to help users find the information they need faster, such as the case of solar cell fabrication details explored in the paper, hence reducing time-to-market.
- Learning Accurate and Interpretable Decision Rule Sets from Neural Networks. A lossless neuro-symbolic method to build decision rules from carefully built Neural Networks.
Bots and Dialog
Bots and assistants are present in many consumer and business software products, hence related research is also very active. Besides the concerns of any NLU software, these systems also have to deal with specific problems, how to hold a coherent conversation over time.
- ⭐️ Lifelong and Continual Learning Dialogue Systems: Learning during Conversation. Most dialog systems learn all they need prior to interacting with users. However, there’s a lot to be learned during conversations, through so-called “on-the-job learning.” Specifically, it is possible to: learn how to ground statements (“Draw a blue circle at (x, y)” -> drawCircle(blue, x, y)); obtain new world knowledge; and even learn new skills from users. The paper provides a number of references that allow further exploration of such possibilities.

- Bootstrapping Dialog Models from Human to Human Conversation Logs. We can learn the dialog model itself from human data.
- MultiTalk: A Highly-Branching Dialog Testbed for Diverse Conversations. What if we wanted to reason about the possible evolutions of a conversation? This dataset supports this. Talking to the authors during the poster session, together we also realized that this is related to branching-time temporal logic (e.g., CTL), which is not something they had thought of! This is just the kind of productive conversation I was hoping for.
- Doc2Bot: A Document Grounded Bot Framework. An approach that help companies that have a lot of user content (e.g., Microsoft, Google) to make them available through bots as well.
Other NLP Highlights
- Unsupervised Opinion Summarization with Content Planning
- Fact-Enhanced Synthetic News Generation
- A Controllable Model of Grounded Response Generation. Grounds text generation on external sources (e.g., Wikipedia), thus reducing the chance of generating spurious content.
- Exploring Transfer Learning for End-to-End Spoken Language Understanding
- 🗃️ Related datasets: Facebook’s Task Oriented Parsing (TOP), Fluent Speech.
- Learning of Structurally Unambiguous Probabilistic Grammars
- Multiplicity Automata: Automata in which states are vectors and transitions are linear transformatons.
- Text-Based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
- TextWorld Commonsense (TWC), the proposed system, is available for download.
- Uses ConceptNet, “an open, multilingual knowledge graph”, which itself looks quite useful.
- Automatic Curriculum Learning with Over-Repetition Penalty for Dialogue Policy Learning. User simulators can be used to learn dialogue policies. Instead of random sampling, however, the paper proposes a method to ensure the simulator covers scenarios according to what maximizes overall learning.
Human and Artificial Behavior
Actions by humans and artificial agents are, of course, more general than what language contemplates. There were many works on how to understand, combine, generate and manipulate behavior.
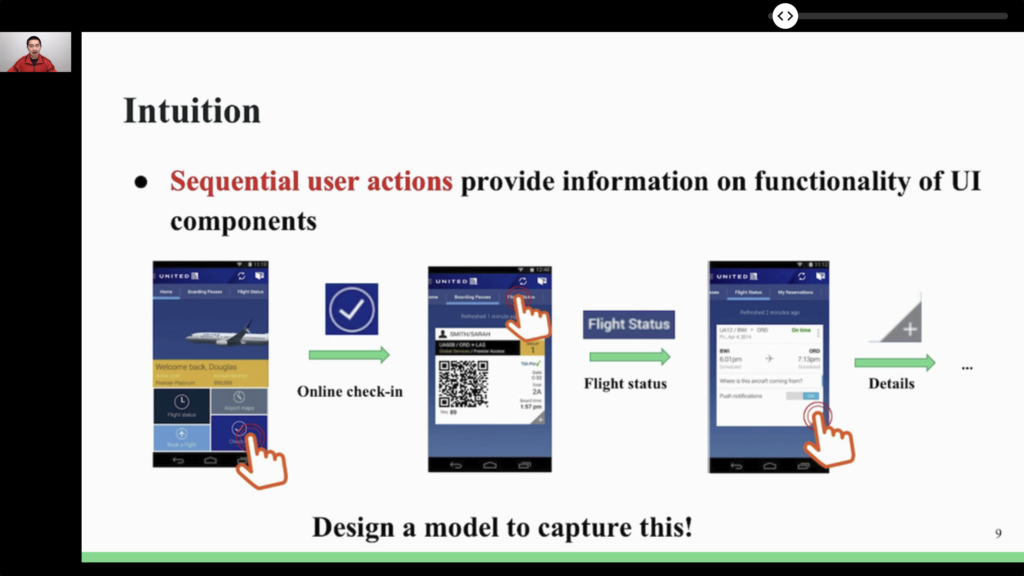
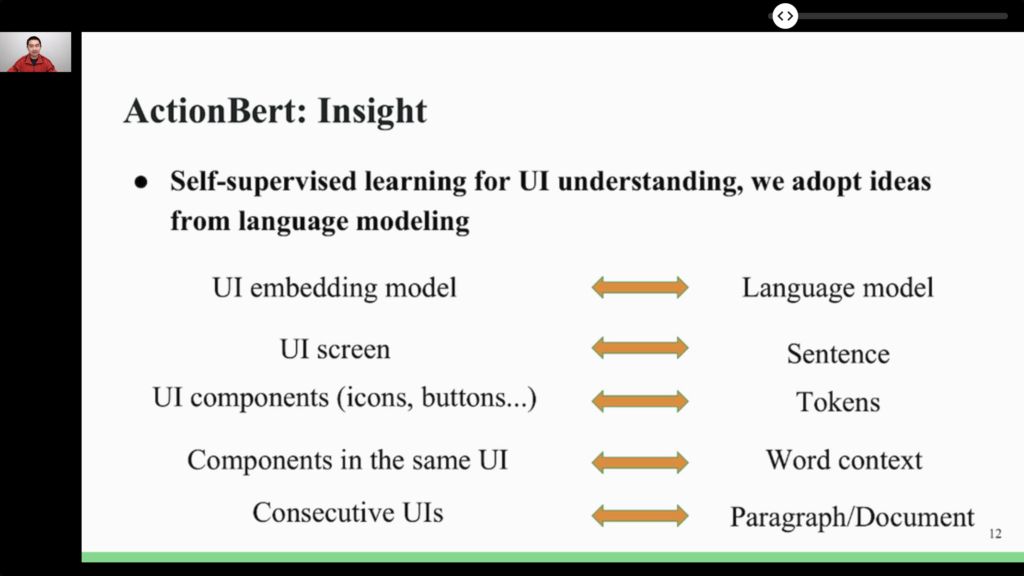
- ⭐️ ActionBert: Leveraging User Actions for Semantic Understanding of User Interfaces. User behavior can be understood as sequences of user actions. From this observation, this work proposes a Transformer model not of text, but of actions! Once pre-trained (using self-supervision), the resulting model can be used in a number of downstream tasks. Because it is so similar to highly successful NLP approaches, it looks like a very promising technique. Furthermore, in this age of privacy-minded legislation, self-supervised pre-training, which can be achieved without human access to the actual data, is valuable.

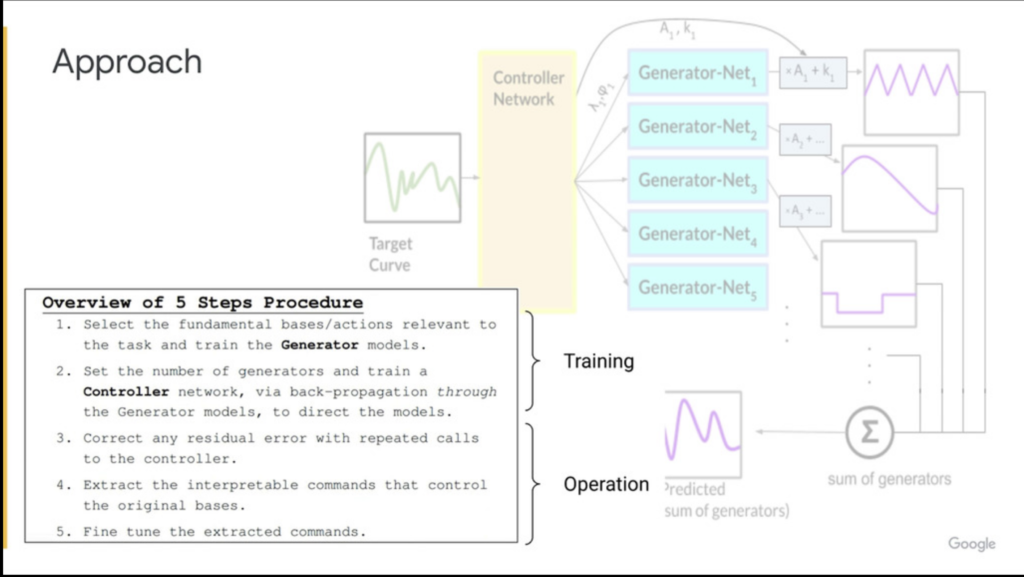
- ⭐️ Interpretable Actions: Controlling Experts with Understandable Commands. Typically, black-box models are interpreted a posteriori, which makes such interpretations tricky. In this work, however, the interpretation is built-in, making later use much simpler and more reliable. By modelling a system as a central controller which acts through the combination of meaningful basis functions, it is possible to train the controller to skillfully employ these actions, thereby ensuring that the system’s behavior can be interpreted as a composition of intelligible parts. Painting is provided as an elegant application.

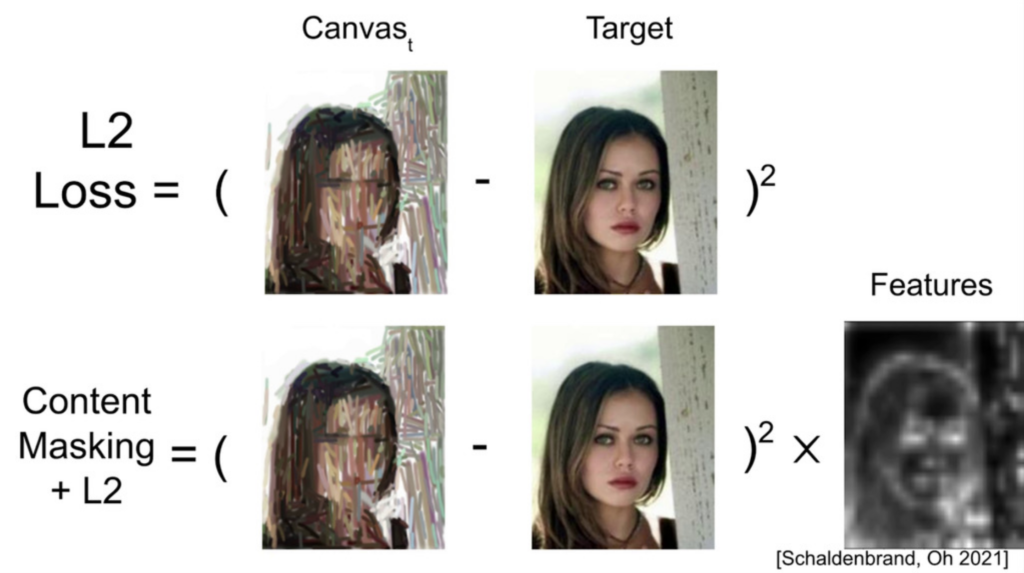
- Content Masked Loss: Human-Like Brush Stroke Planning in a Reinforcement Learning Painting Agent. Similar to the previous one, this work also uses painting as a case study. Here, however, the objective is to have a sequence of actions that is closer to what human painters would employ, which means a gradual change in the abstraction level (i.e., at any point of the action sequence, there’s a meaningful version of the subject). The trick is to detect the main features of the subject and increase the reward for considering them. The authors experiment with a number of variations of this strategy.
- ⭐️ Advice-Guided Reinforcement Learning in a Non-Markovian Environment. Human-authored specifications can improve Reinforcement Learning. Conversely, the during RL execution, the algorithm can find errors in the specification and correct them. Thus, it is an elegant way to combine human insight with algorithmic power, one of my favorite themes. This reminds me of last year’s paper, Restraining Bolts for Reinforcement Learning Agents.
- Comparison Lift: Bandit-Based Experimentation System for Online Advertising. An Experimentation-as-a-Service (EaaS) system (I like this term) which improves the notion of A/B tests by also selecting the best audiences and the best creatives to deliver. The authors claim that their method led to 27% more clicks than usual A/B tests at JD.com.
- The AAAI 2021 Workshop on Plan, Activity, and Intent Recognition (PAIR2021). Automated Planning and Scheduling is a traditional theme in AI. In this workshop, this know-how is used with the aim of recognizing user intents and goals. It is yet another fruitful combination of different fields.
- I also discovered a planner: PANDA Planning System
- There’s a recent book on the subject of Planning: Automated Planning and Acting
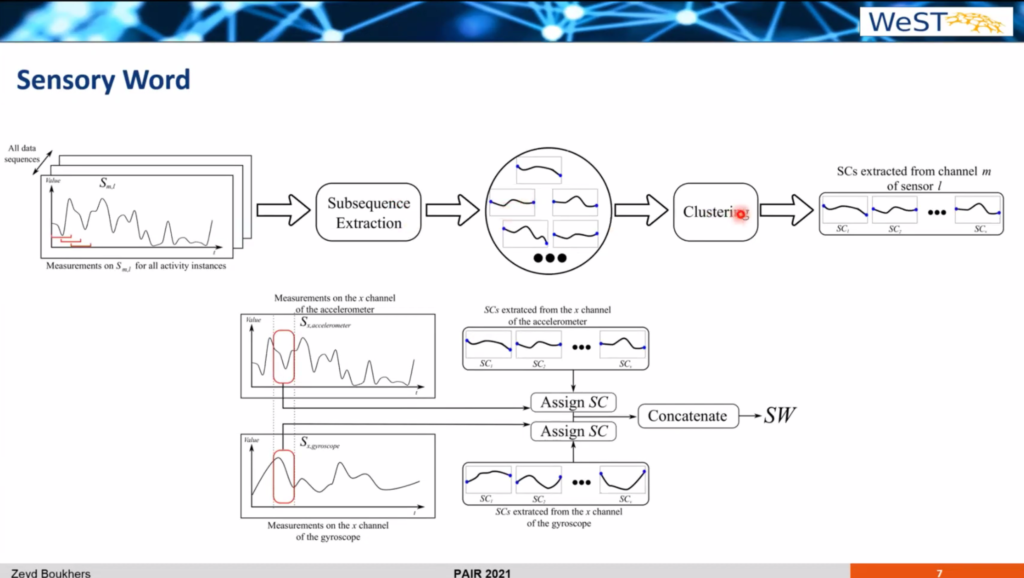
- LaHAR: Latent Human Activity Recognition using LDA (PAIR2021). An approach for unsupervised activity recognition using “sensory words” built from accelerometer and gyroscope smartphone data.
- 🗃️ Related dataset: UCI Human Activity Recognition Using Smartphones.
- 🗃️ Related dataset: UCI Human Activity Recognition Using Smartphones.
- Adaptive Agent Architecture for Real-time Human-Agent Teaming (PAIR2021). A multiagent approach to selecting and evaluating agent policies in order to maximize the overall team (human + artificial agents) performance.
- The AAAI-21 Workshop on AI For Behavior Change. Behavioral economics has been very influential recently, and its implications and insights are now felt in AI as well, as was explored in this workshop.
- In the talk “Can Algorithms Help Us Better Understand Ourselves?” (Sendhil Mullainathan), it was pointed out that many people think that physicians over-prescribe laboratorial exams and therefore one should aim to reduce such prescriptions. However, it turns out that they also under-prescribe such exams, and the optimal course of action (in terms of patient outcome) is thus actually different. Machine Learning tools can help us understand why and how we do certain things, which helps in improving our behavior. See his paper: A Machine Learning Approach to Low-Value Health Care: Wasted Tests, Missed Heart Attacks and Mis-Predictions
- In her talk “Designing and Analyzing Large Scale Experiments for Behavior Change”, Susan Athey showed how experimental interventions can be designed to change human behavior. As an example, she showed how to reliably increase charitable donations.
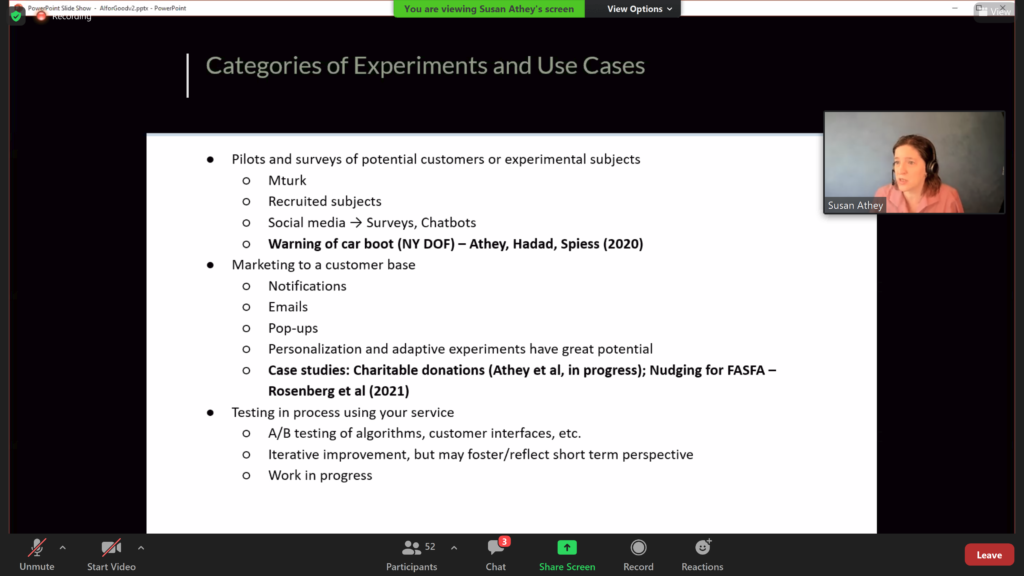
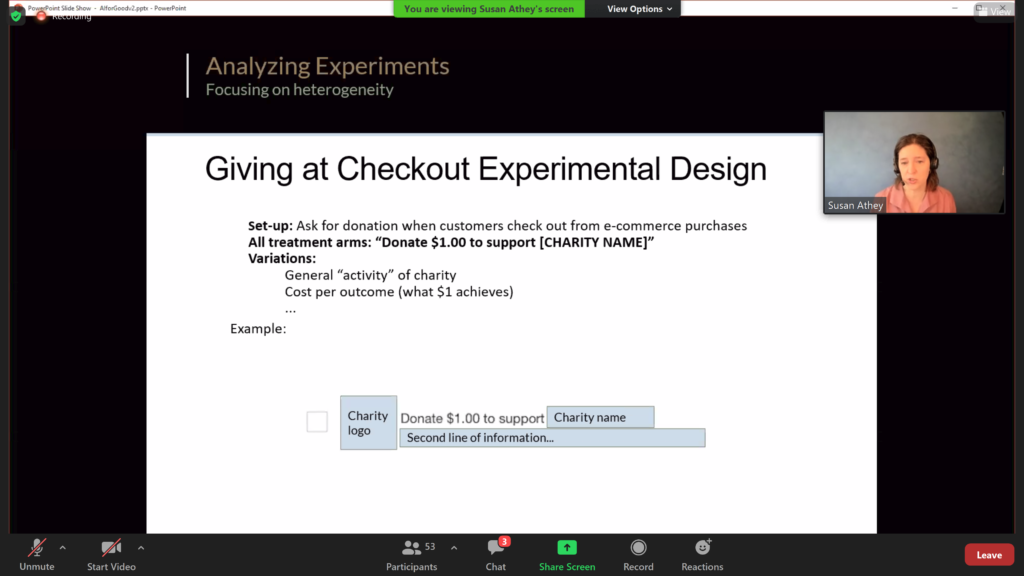
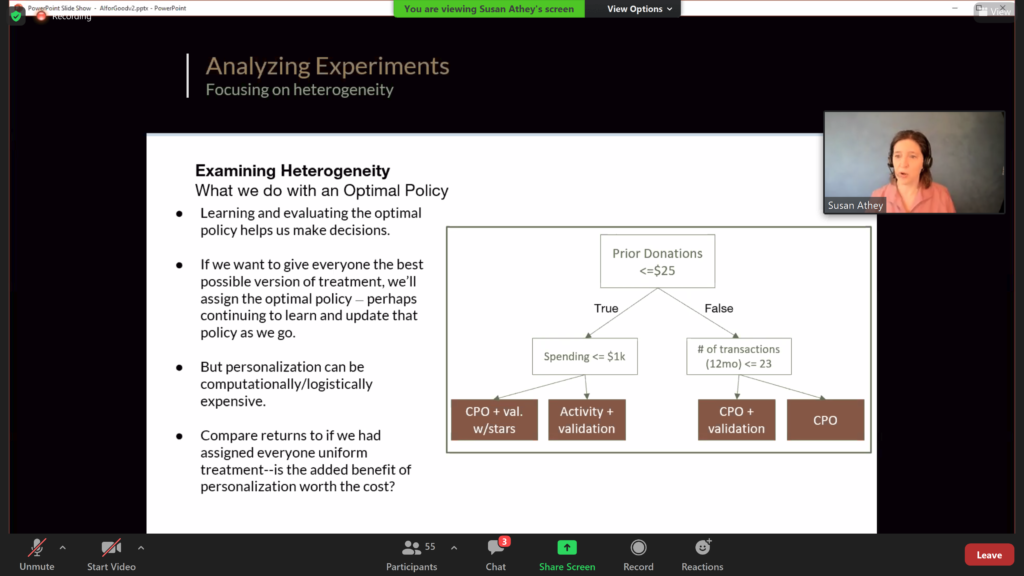
- The AAAI-21 Workshop on Content Authoring and Design (CAD21). One specific way in which humans can benefit from AI support is on content creation, such as graphical design. This has clear applications, for instance, in the creation of slide presentations (e.g., PowerPoint). This workshop examined a number of such approaches.
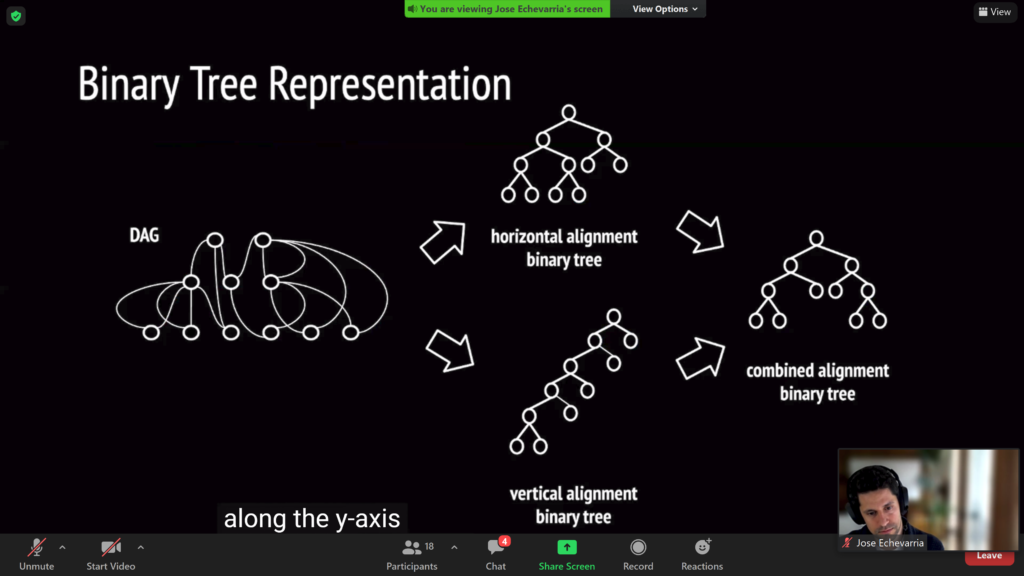
- In Automatic Generation of Typographical Layouts (CADS21) the author explored a technique layout generation using trees.
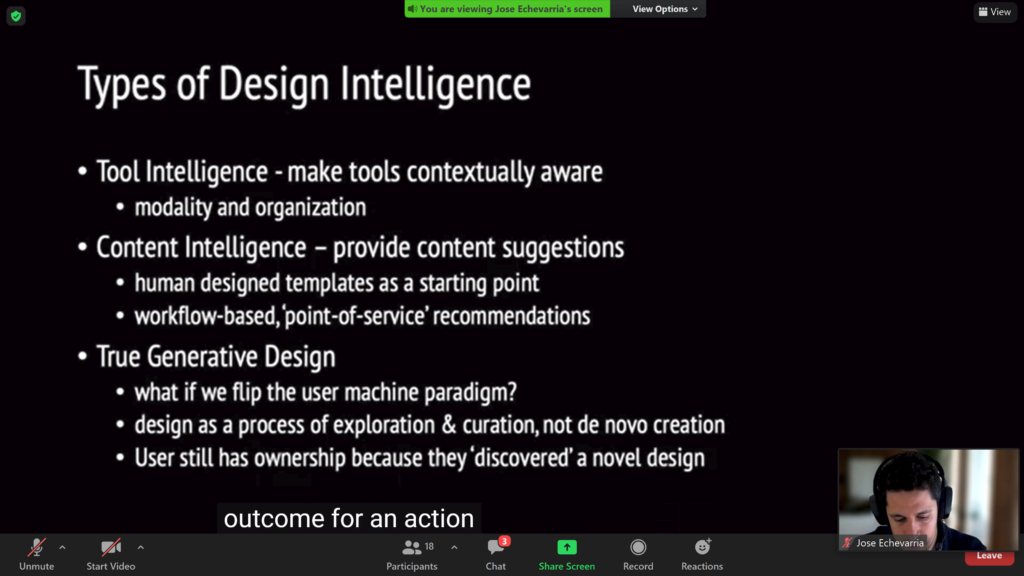
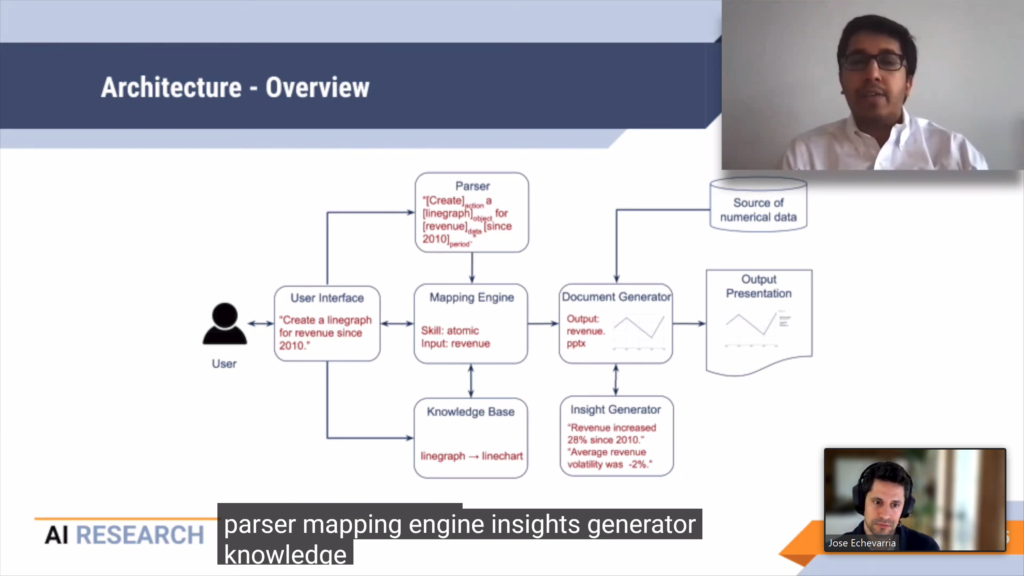
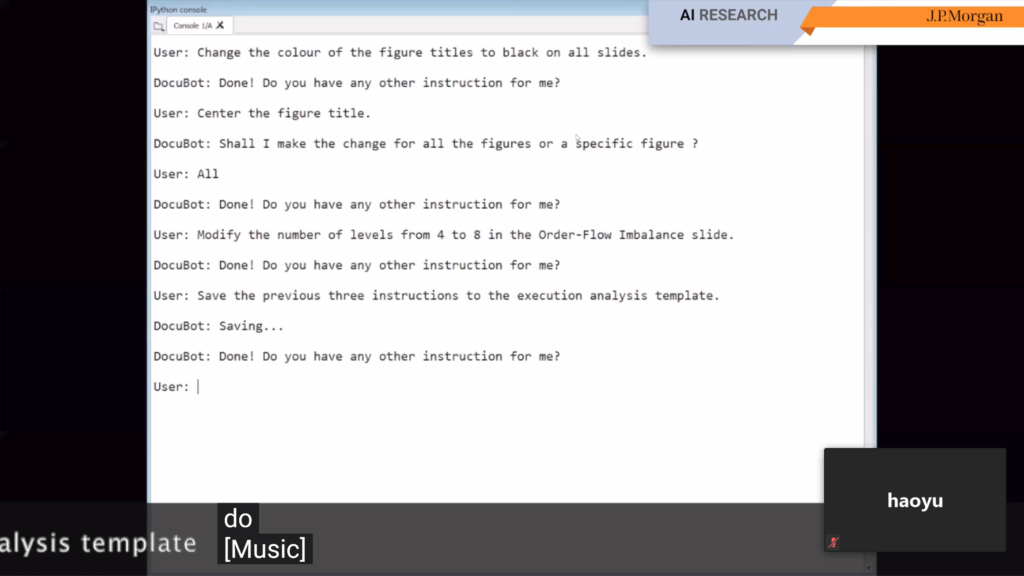
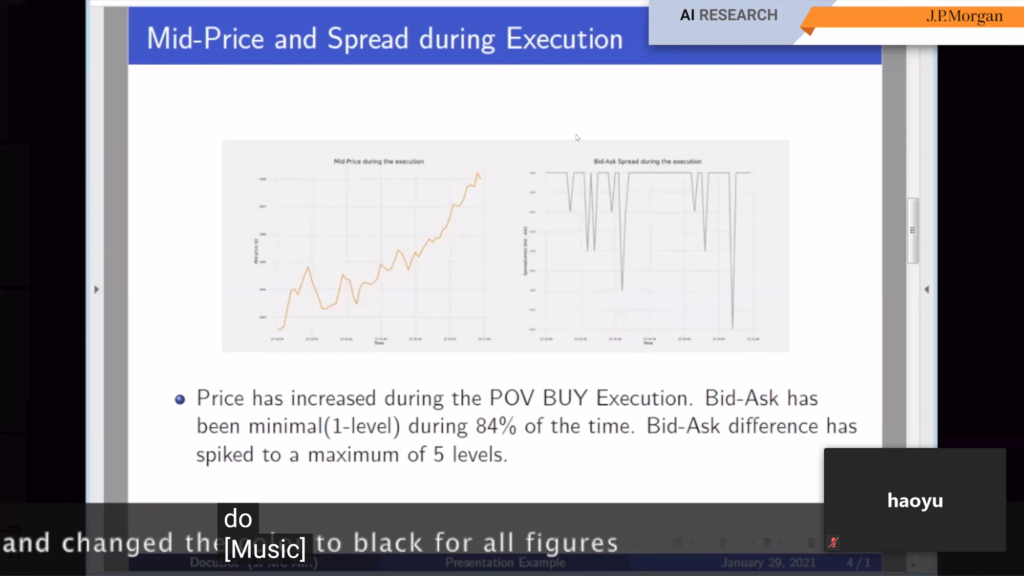
- In DocuBot: Generating financial reports using natural language interactions it is shown how J.P. Morgan developed an interactive bot to generate complete slide decks from human commands.
- I am particularly interested in such content generation and optimization through user interaction. Notably, in 2017 I published User Interface Optimization Using Genetic Programming with an Application to Landing Pages (local download) at EICS 2017.
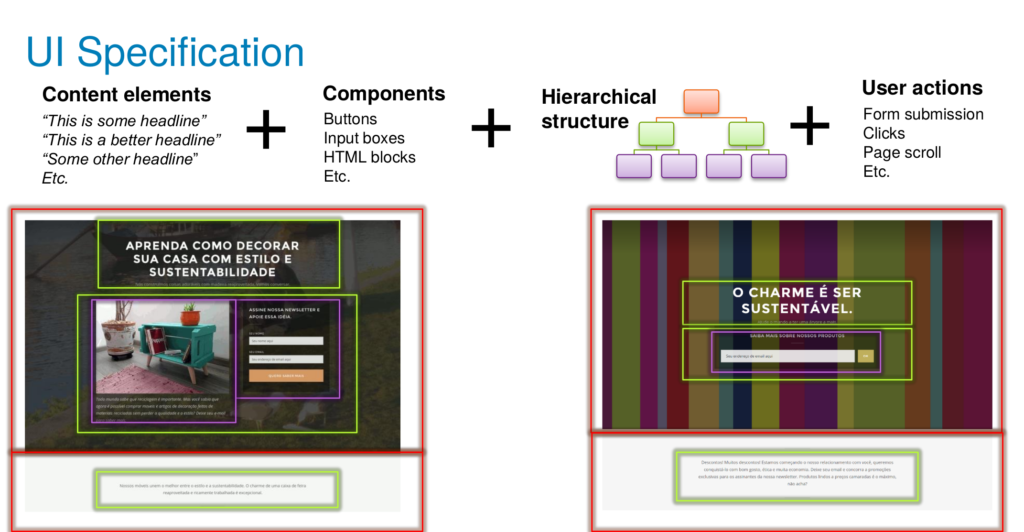

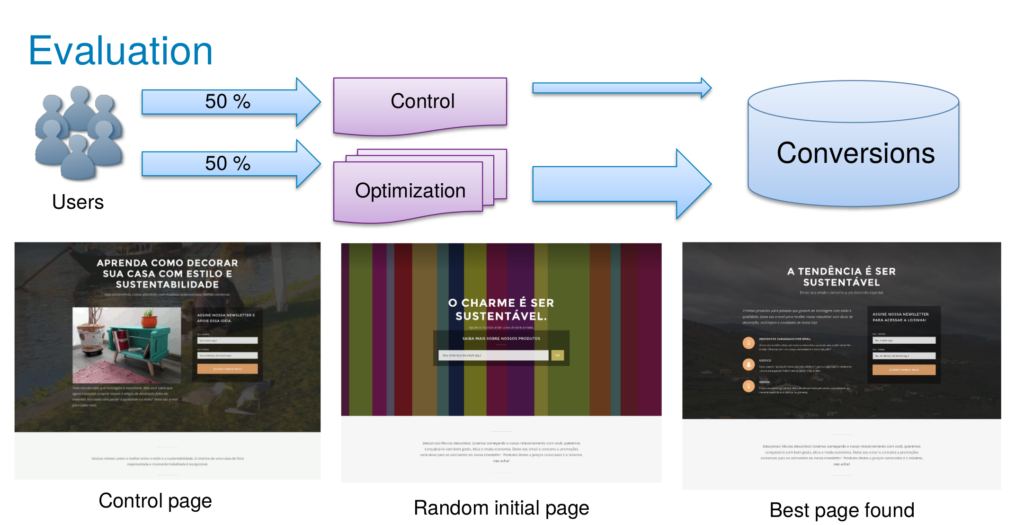
Other Business Problems
As interesting as the above general themes might be, some developments which are highly relevant to business have little to do them. Let’s review some here.
- Time series: ⭐️ TODS: An Automated Time Series Outlier Detection System (paper). Time series are everywhere in business. A lot of existing work is focused on prediction and generation. Here, however, we have a system for outlier detection, a task which is often critical when dealing with time series. Data Scientists often go for simple outlier definitions, and it is helpful to have libraries to assist them in doing better than this. TODS is actually a practical toolkit, available for download, which allows the careful programming of outlier detection pipelines.
- Still concerning time series, there was a panel on Forecasting in Unprecedent Times, motivated by the huge change in behavior brough by the COVID-19 disruption, of which I took a few insights:
- When models become obsolete or must be rebuilt quickly with fresh data, explainability becomes important, because it is necessary for experts to input knowledge and validate existing assumptions and result.
- In supply chain management, because such chains are so complex and depend on so many parts, one is supposed to be always ready to counter any problem. Hence, there are playbooks about what to do under various scenarios (e.g., we were told some customers have, say, 200 different scenarios). Simulations are crucial to build such scenarios.
- It is important to capture uncertainty of models, not only their point estimates. This is actually valued by real customers, because it helps them to take calculated risks, as I learned firsthand some months ago too (in healthcare cost estimation).
- Models under continually changing regimes are hard to maintain. The notion of war-time models vs peace-time models was introduced to account for this, and everybody thought it was a interesting way to put it.
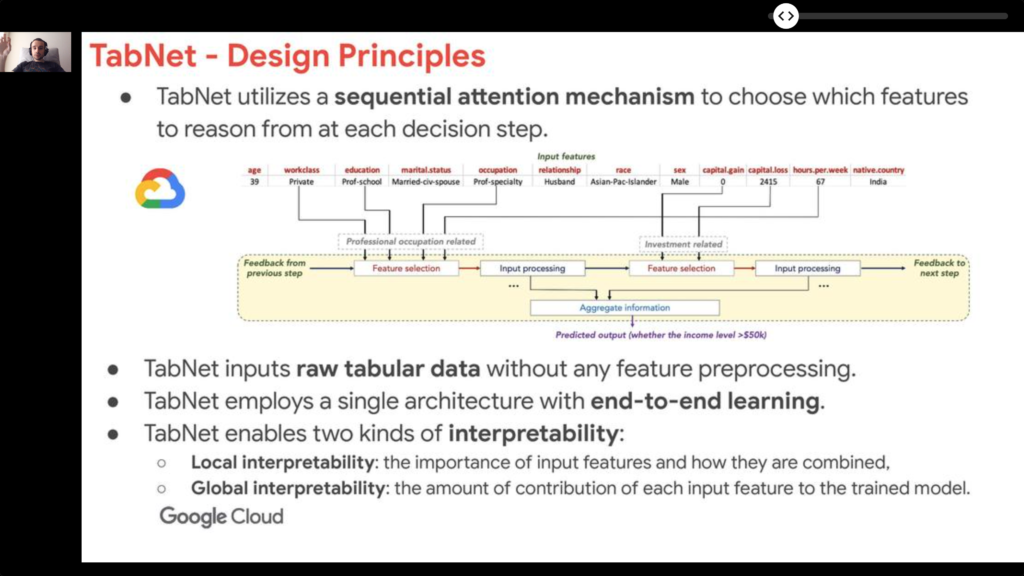
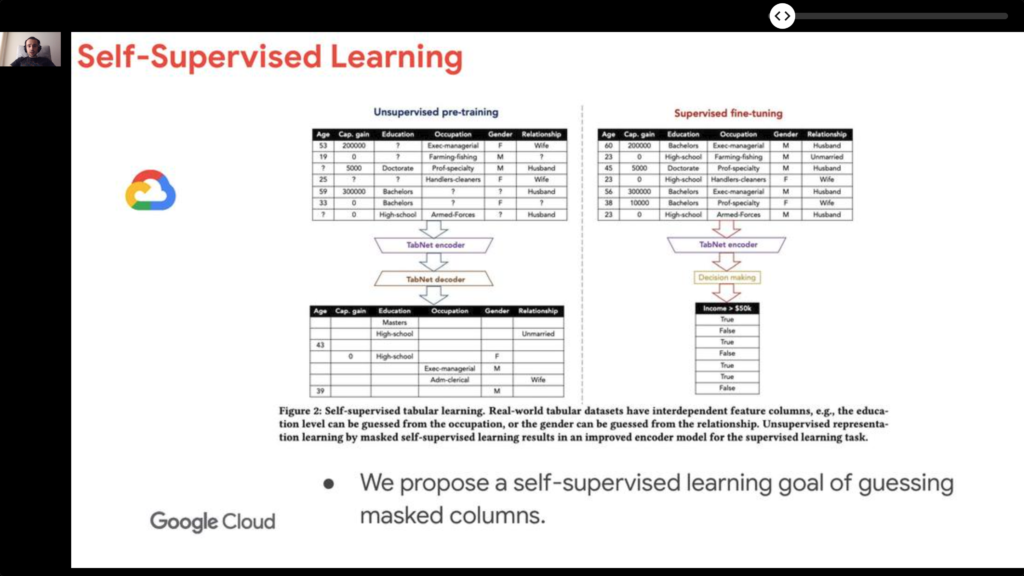
- Tabular data: ⭐️ TabNet: Attentive Interpretable Tabular Learning. Tabular data dominates the business world, yet recent advances in Deep Neural Network paid little attention to them. This work proposes to remedy this, for example with attention mechanisms for the selection of columns at appropriate moments, and self-supervision for training.

- This book on alternative data for finance was highly recommended in a panel (which included the author, though): The Book of Alternative Data: A Guide for Investors, Traders and Risk Managers
Techniques: Meta Learning, AutoML, Graphs Neural Networks and Causal Inference
Besides more application-oriented content reviewed above, I also gained a lot of insight into techniques themselves. I tried to prioritize methods which are relatively new and promising.
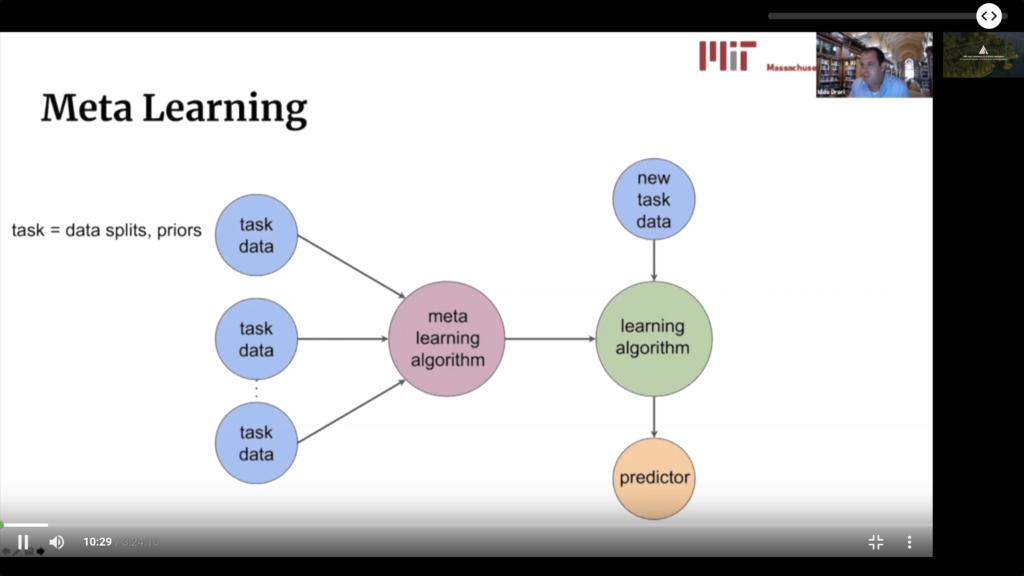
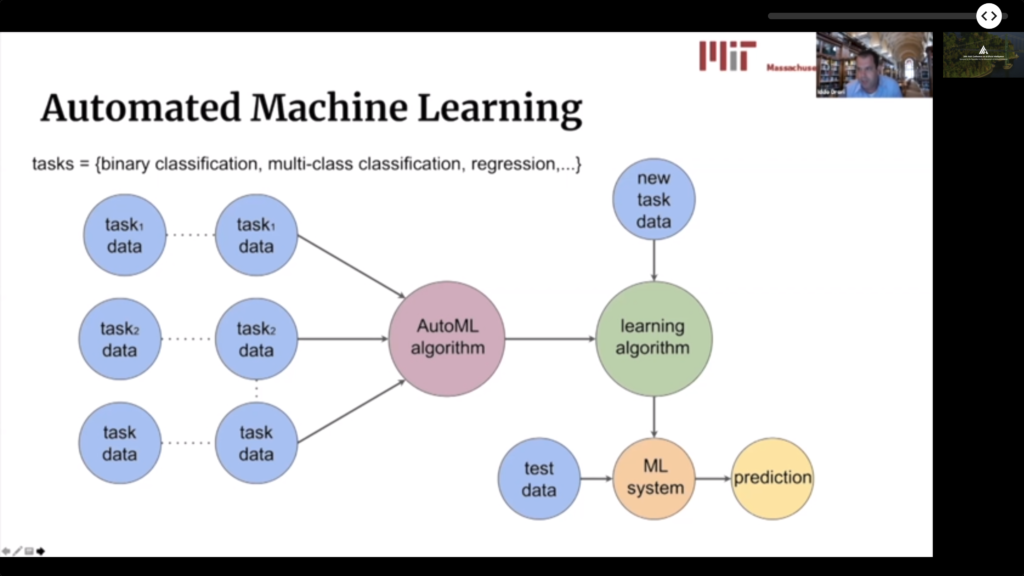
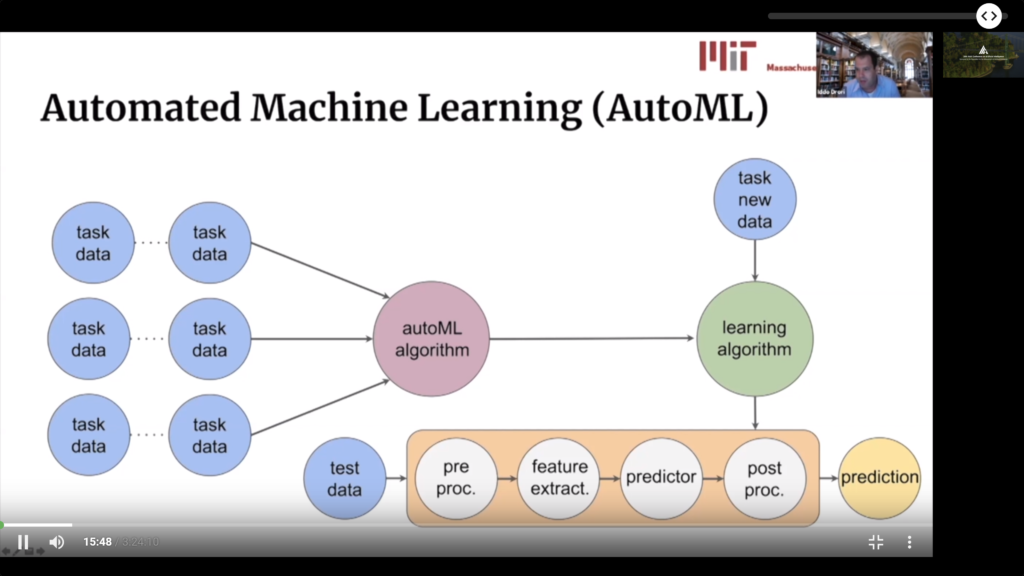
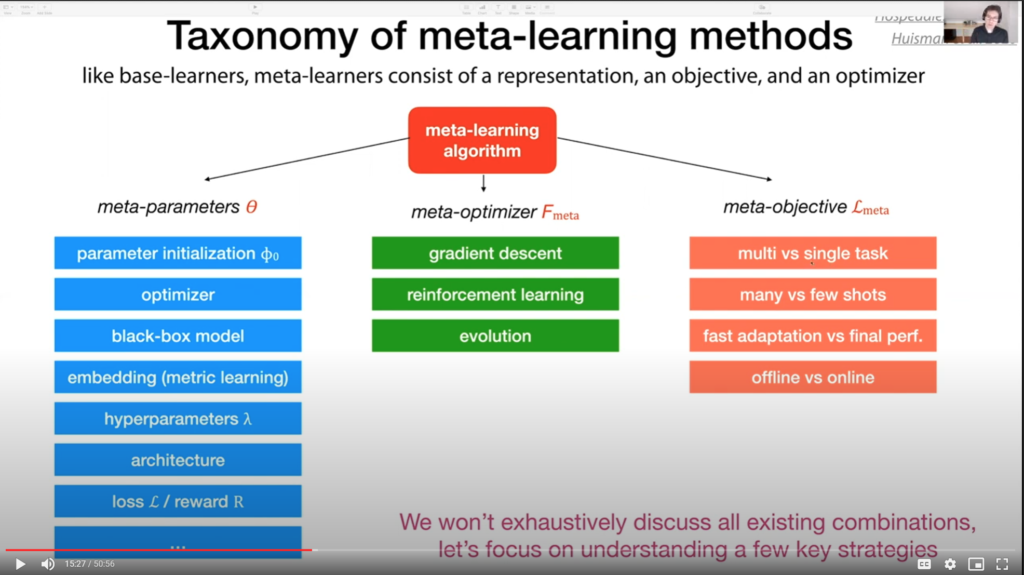
Meta Learning and AutoML
Learn about learning seems like a very logical extension of traditional Machine Learning. It is also very important to empower regular users and increase the productivity of professional Data Scientists.
- There was an excellent Tutorial on Meta Learning.
- Every such learning approach has some bias, and in learning to learn the same is true. The difficulty is in how much bias is needed for useful generalization.
- Curiously, a lot of the metalearning seems to relate to good feature engineering. Under some conditions, a good embedding scheme + traditional learning algorithms is equivalent to metalearning.
- Tasks can be embedded too.

- There is a lot of confusion about the relationship of Meta Learning and AutoML. The turorial argues, rather well I believe, that each body of work is actually addressing a different and complementary problem. So these are different but symbiotic fields.
- Curriculum learning (or optimization) is a refreshing idea. We often consider how to make learners somehow better, but ignore the context in which they learn. What if we optimized the learning environment instead? For instance, by finding the best tasks to induce learning. In fact, I have argued elsewhere (see A Formal Environment Model for Multi-Agent Systems [local download]) about the importance of carefully considering environments as first-class entities, though not in the context of Machine Learning.
- Humans naturally pick tasks can leverage previously learned tasks.
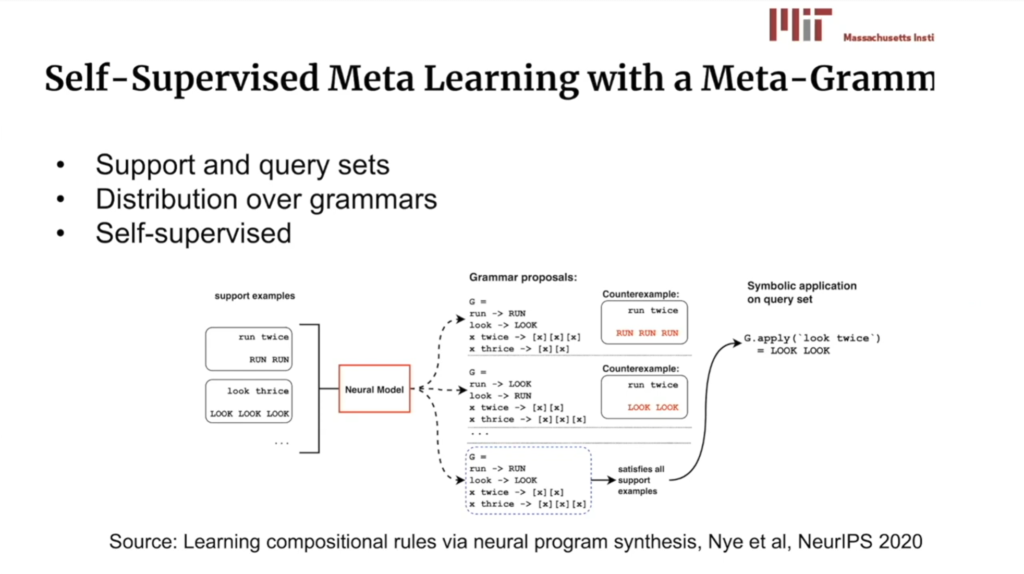

Graph Neural Networks (GNN)
As every Computer Scientist knows, graphs are everywhere. So it is not surprising that Graph Neural Networks (GNN) are ever more important. I did not focus my attention on this theme, but it is worth digging deeper.
- Tutorial: Graph Neural Networks – Models and Applications
- Applications include: drug design (molecules are graphs), social network analysis, recommendation systems and knowledge graphs processing.
Causal Inference
Many believe that causal reasoning is essential for truly intelligent action. This view is becoming ever more popular, so it is no surprise to find many interesting approaches here.
- Improving Causal Inference by Increasing Model Expressiveness. Despite the importance of Causal Inference, causal model are surprisingly inexpressive. The authors argue about a number of important elements that should be included and use the Angry Birds game as illustration.


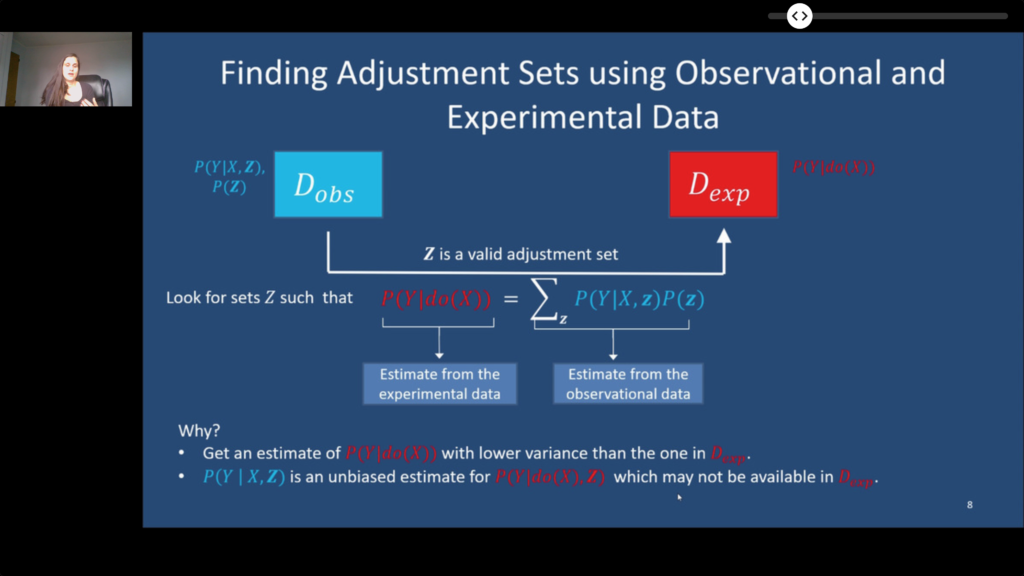
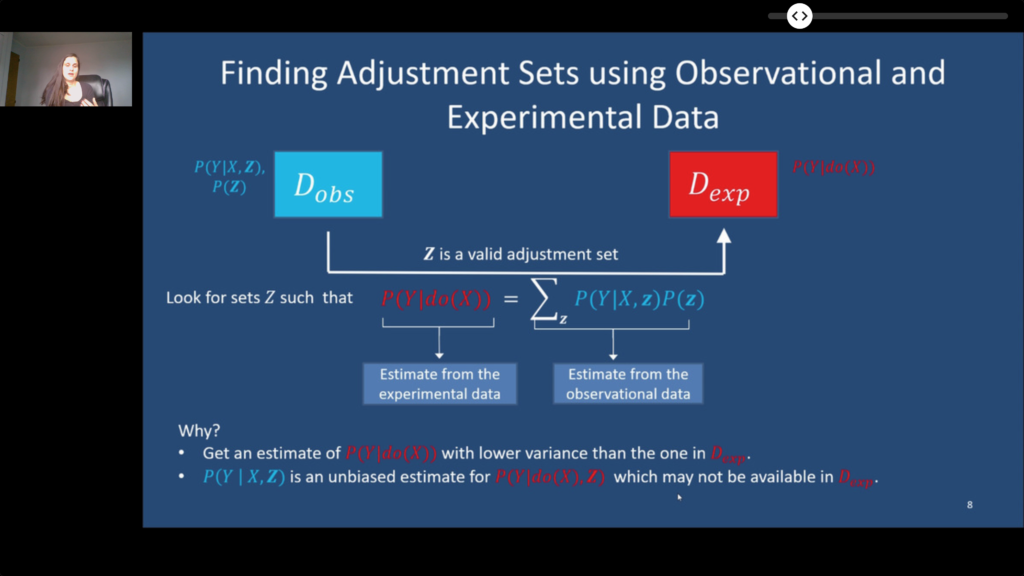
- Learning Adjustment Sets from Observational and Limited Experimental Data. Observational and Experimentation data can be combined in order to obtain more reliable results.
- Improving Commonsense Causal Reasoning by Adversarial Training and Data Augmentation.
- 🗃️ Related to Choice of Plausible Alternatives (COPA) task and dataset.
- Employs GPT-2 for generating training data.
- Disturbs training data with synonyms too.
- A Generative Adversarial Framework for Bounding Confounded Causal Effects. Confounding undetectable from data can jeopardize causal analyses. This method is a way to explore possible confounding effects in order to estimate bounds for what is available in the observational data.
Other Works and Philosophical Aspects
A few other interesting observations and papers that do not fit the above.
- In his talk What Can and Should Humans Contribute to Superhuman AIs?, Tuomas Sandholm made a few noteworthy controversial remarks:
- Applications vs Research: Applications have the fundamental function of bringing important research questions to light. Thus, in many situations applications should drive research, not the other way around, as many researches assume. As an example, he told us how academic bid specification languages were useless in practice and his company had to recreate them taking into account the input of real businesses.
- Occam’s razor is obsolete: there’s no reason why simple theories should always be preferred. In certain situations, in fact, theories can become exponentially long, which means that the problem statement itself challenges human understanding. As an example, he cited characterization theorems in (automated) auction mechanisms.
- Human evaluation is becoming obsolete: as AI solutions become more sophisticated, human evaluation of their validity become increasingly less useful, and even detrimental – so we should not insist in interpretability. This is a kind of superhuman boundary. Humans should, instead: provide a value system; iterate over results of utility functions; provide some solution pieces for later composition; don’t micromanage AI systems.
- Explanatory gap: most people accept and trust systems without really understanding them. Most people can’t, for example, correctly draw a bicycle, according to Sendhil Mullainathan. So interpretability is not why people trust things, hence perhaps not so important in ML after all. This echoes Tuomas’ points above.
- Moreover, as Jon Kleinberg emphasized in his talk, people have a hard time justifying their own actions. Algorithms at least are written down and can be deeply probed. So who’s more trustworthy, a supposed expert or an inscrutable Neural Network that has a better track record?
- Of course, many others argued for interpretability, as can be seen in a number of remarks above.
- Variational Disentanglement for Rare Event Modeling. Rare events and unbalanced datasets are a well-known hindrance for data scientists. This work helps in maximizing the information that can be obtained from them, with an application to disease prediction (e.g., COVID-19).
- Learning Prediction Intervals for Model Performance. Model performance can change over time because of distribution drift. This work proposes a way to estimate the quality of predictions under such conditions, without the need of human supervision, thus aiding in model monitoring.
- Combinatory Categorial Grammar. Apparently, an efficiently parsable and linguistically expressive grammar type. Sounds interesting because it is more powerful than context-free grammars.
- Ablation studies were used in various papers to study the effect of specific mechanisms of the proposed approaches. By removing the mechanism of interest and examining the difference in results, it is possible to infer what the removed mechanism contributed to. Rather like the study of the brain when imaging techniques were not available.
- Complex simulations are often used for training and validation. Hence, I expect (or at least would love to see) that simulation communities will gradually get closer to the AI ones.